Journal influence
Bookmark
Next issue
The temporal restrictions satisfaction methods in intelligent decision support systems of real time
The article was published in issue no. № 1, 2010Abstract:The temporal restrictions satisfaction methods based on anytime algorisms of decision making oriented towards the intelligent decision support systems of real time are considered.
Аннотация:Рассматриваются методы поиска решения на основе гибких алгоритмов, ориентированные на применение в интеллектуальных системах поддержки принятия решений реального времени.
| Authors: Eremeev, A.P. (eremeev@appmat.ru) - National Research University “MPEI” (Professor), Moscow, Russia, Ph.D, (eremeev@appmat.ru) - | |
| Keywords: anytime algorithms, real time, decision making, intelligent systems |
|
| Page views: 15230 |
Print version Full issue in PDF (4.03Mb) Download the cover in PDF (1.25Мб) |
Интеллектуальные системы поддержки принятия решений (ИСППР) реального времени (РВ) предназначены для помощи ЛПР при мониторинге и управлении сложными объектами и процессами в условиях достаточно жестких временных ограничений [1–3]. К таким объектам относятся и объекты энергетики. Одной из главных задач ИСППР РВ является помощь ЛПР для удержания объекта в рабочем (штатном) режиме функционирования и возвращения его в штатный режим при возникновении каких-либо отклонений. В [2] предложено конструировать ИСППР РВ как интегрированные интеллектуальные системы семиотического типа, сочетающие строгие, формальные методы и модели поиска решений с нестрогими, эвристическими методами и моделями, базирующимися на знаниях специалистов-экспертов, моделях человеческих рассуждений (как достоверных, так и правдоподобных), имитационных моделях, неклассических логиках и накопленном опыте. ИСППР РВ используются при оперативном управлении сложными системами и процессами в открытых и динамических предметных/проблемных областях и ориентированы на решение плохо формализуемых, слабоструктурированных задач при отсутствии полной и достоверной информации. Специфика таких задач в следующем: · невозможность получения всей объективной информации, необходимой для решения, и в связи с этим использование субъективной, эвристической информации; · данные задачи являются комбинаторными, многие из них относятся к классу NP-полных; · присутствие недетерминизма в процессе поиска решения; · необходимость коррекции и введения дополнительной информации в процессе поиска решения, активное участие в нем ЛПР; · необходимость получения решения в условиях достаточно жестких временных ограничений, определяемых реальным управляемым процессом.
Решением данной задачи является нахождение наиболее приемлемого варианта (альтернативы) из возможного множества альтернатив. Решение, основанное на знаниях, – это решение, при поиске которого используются содержащиеся в БЗ интеллектуальной системы знания и накопленный опыт (хранящийся, в частности, в базе прецедентов и аналогов). В качестве критерия эффективности методов поиска решения на основе заложенных в систему знаний в ИСППР РВ, как правило, служит критерий достижения наилучшего качества (и обоснованности) вырабатываемых вариантов решений за отведенное время. Поэтому одним из важнейших требований к таким системам является обеспечение гарантированного времени на поиск решения. В данной работе исследуются подходы к задаче поиска решения, наилучшего в условиях задаваемых временных ограничений, что специфично для систем РВ. Архитектура ИСППР РВ Обобщенная архитектура ИСППР РВ представлена на рисунке 1. ИСППР РВ является системой распределенного интеллекта, состоящей из взаимодействующих между собой интеллектуальных блоков (модулей), выполняющих соответствующие интеллектуальные функции [2]. К числу таких блоков, помимо традиционных для интеллектуальных систем БД и БЗ, блоков поиска решения, приобретения и накопления знаний, объяснения и прочего, относятся блоки моделирования проблемной ситуации, обучения, прогнозирования, связи с внешними объектами (датчиками, контроллерами, концентраторами данных, управляющими приводами и т.д.), средства организации различного типа интерфейсов (образного, текстового, речевого, в виде графиков и диаграмм и т.д.) с пользователями (ЛПР, экспертом, инженером в области знаний). К интеллектуальным относятся и функции поиска (вывода) решения на базе моделей и методов представления и оперирования динамическими знаниями, характеризующимися различными так называемыми НЕ-факторами (неточностью, нечеткостью, недостоверностью, неполнотой, противоречивостью и др.). Поиск решения осуществляется с использованием механизмов эвристического поиска и методов неклассических логик (нечетких, индуктивных, абдуктивных, темпоральных, логики аргументации, на основе аналогий и прецедентов), а также механизмов обучения и пополнения знаний [1–4]. ИСППР семиотического типа может быть задана набором SS = , где M={M1,…,Mn} – множество формальных или логико-лингвистических моделей, реализующих определенные интеллектуальные функции; R(M) – множество правил выбора необходимой модели или совокупности моделей в текущей ситуации, то есть правил, реализующих отображение R(M): S®M, где S – множество возможных ситуаций (состояний), которое может быть и открытым, или S'®M, где S' – некоторое множество обобщенных ситуаций (состояний), например, нормальных (штатных), аномальных или аварийных, при попадании в которые происходит смена модели; F(M)={F(M1),…,F(Mn)} – множество правил модификации моделей Mi, i=1,…,n. Каждое правило F(Mi) реализует отображение F(Mi): S''´Mi®M'i, где S''ÍS, M'i – некоторая модификация модели Mi; F(SS) – правило модификации собственно системы SS – ее базовых конструкций M, R(M), F(M) и, возможно, самого правила F(SS), то есть F(SS) реализует целый ряд отображений (или комплексное отображе- ние) F(SS): S'''´M®M', S'''´R(M)®R'(M), S'''´F(M)®F'(M), S'''´F(SS)®F'(SS), где S'''ÍS, S'''ÇS'=Æ, S'''ÇS''=Æ, то есть правила модификации данного типа используются в ситуациях, когда имеющихся множеств моделей, правил выбора и правил модификации недостаточно для поиска решения (решений) в сложившейся проблемной ситуации. Причем для модификации F(SS) могут использоваться как внутренние средства порождения моделей и правил (гипотез), так и внешние метазнания, отражающие прагматический аспект проблемной ситуации [2]. Сформулируем задачу принятия решений как задачу эвристического поиска на основе знаний последовательности действий, выполнение которых удерживает контролируемый объект в нормальном (штатном) режиме функционирования, а также возвращает его в нормальный или максимально приближенный к нормальному режиму при возникновении каких-либо отклонений. Требования систем реального времени накладывают на данную задачу поиска дополнительные временные ограничения. Решение, найденное несвоевременно, чаще всего не имеет практической пользы. Поэтому принимаемое решение, во-первых, должно быть наилучшим среди возможных альтернатив, а, во-вторых, своевременно принятым, то есть процесс его поиска должен удовлетворять некоторым временным ограничениям T. Строгие алгоритмы могут искать точное (оптимальное) решение задачи в течение долгого времени, не удовлетворяющего заданным ограничениям T, однако зачастую достаточно хорошее и приемлемое приближенное решение может быть найдено за значительно более короткое время. Поэтому в качестве основного подхода к решению поставленной задачи предлагается использовать механизм гибких вычислений (алгоритмов) [5–7]. Гибкими называются алгоритмы, качество найденных результатов которых улучшается с увеличением времени работы алгоритма. Гибкие алгоритмы можно выполнять двумя способами: либо с заранее предусмотренным лимитом времени выполнения (контрактные вычисления), либо с возможностью останова в любой момент (гибкие вычисления). Выполнение обоих видов алгоритмов всегда можно продолжить после того, как они были остановлены (либо по истечении лимита времени, либо из-за прерывания) для поиска лучшего решения. Гибкий алгоритм обладает такими свойствами, как · многозначность функции качества Q(r), определенная для любого возвращаемого результата и позволяющая более эффективно распределять компьютерные ресурсы; · прерываемость и возобновляемость – алгоритм, остановленный в произвольный промежуток времени, возвращает лучшее из найденных на текущий момент решений; · предсказуемость, позволяющая приближенно оценить качество результата, возвращаемого алгоритмом, при заданной продолжительности его работы; · устойчивость – качество решения алгоритма коррелирует со временем вычисления и качеством входных данных. При поиске решения можно сократить время поиска, снизив качество решений, в том числе за счет: · снижения полноты обрабатываемой информации (игнорирование или неполный учет некоторых подцелей, условий, требований, ограничений); · уменьшения обоснованности решений (некоторые варианты решений анализируются с меньшей глубиной проработки или отбрасываются без оценивания, не рассматривается ряд поддерживающих или отвергающих отдельные элементы решений факторов, показатели и критерии выбора решений не адаптируются к сложившейся ситуации и т.п.); · уменьшения точности решений за счет приближенного определения их вариантов [7]. Учитывая сказанное, предлагается выполнять поиск решения с помощью определенной последовательности этапов и процедур, между которыми существуют прямые и обратные связи. 1. Выявление и анализ проблемной ситуации. На основе исходной информации о состоянии системы (S) и внешней среды (E) определяются место и роль анализируемых объектов среди смежных объектов и объектов более высокого порядка, осуществляются выявление, структуризация и ранжирование проблем: S×E→Pr. 2. Формирование временных ограничений. На основе информации о состоянии системы и списка проблем формируется множество временных ограничений T, которым должен удовлетворять алгоритм поиска решения: S×Pr→T. 3. Формирование множества допустимых действий. На основе информации о состоянии системы определяется как можно более полное множество действий A для решения всевозможных проблем: S×Pr→A. Следует отметить, что при достаточно большом количестве альтернатив увеличивается время поиска, но вместе с тем появляется гарантия, что в этом множестве содержится наиболее эффективное решение. Небольшое количество альтернатив, естественно, уменьшает трудоемкость анализа, однако при этом увеличивается вероятность совершения грубой ошибки, связанной с нахождением неэффективного решения. В ИСППР РВ необходимо найти приемлемый компромисс между качеством предлагаемого решения и временем, затраченным на его нахождение. 4. Формирование плана решения задачи. Для решения задачи необходимо составить план его поиска, состоящий из компонентов, имеющих конкретную временную и адресную привязку. Для этого предназначен планировщик PLAN, способный на основе результатов, полученных на предыдущих шагах, и некоторой модели системы сформировать план решения задачи, адаптивно выбирать (формировать) рациональную последовательность выполняемых процессов и для каждого отдельного процесса или процедуры реализовывать наиболее приемлемые модели и алгоритмы, позволяющие получать решения в рамках отведенного времени с требуемым (или максимально достижимым) качеством. Реализация механизмов удовлетворения временных ограничений с помощью гибких алгоритмов осуществляется на всех этапах поиска решения – от анализа проблемной ситуации до формирования плана решения задачи. Обобщенный алгоритм работы планировщика PLAN представлен на рисунке 2. Рассмотрим основные шаги гибкого алгоритма, реализованного в планировщике PLAN. Шаг 1. Выбор, генерация и (или) модификация модели M поиска решения. Множество действий А, выявленное на этапе 3, проходит через фильтр временных ограничений T, полученных на этапе 2. Для этого используется модификация модели (системы) удовлетворения временных ограничений, предложенной в [7]: TC=, где A – множество анализируемых действий; Tпд={tпk} – временные ограничения (tпk – допустимое время выполнения k-го этапа, k=1,...,N, N – количество этапов решения); Mп={mi} – модели реализации вычислительных процедур для поиска, учитывающие условия их выполнения, привлекаемые силы и средства и т.п.; R={rlt} – имеющиеся вычислительные ресурсы (rlt – количество ресурсов l-го типа в момент t); PPn – профили производительности процедур поиска решения (ожидаемое качество результата в зависимости от временных затрат при использовании процедуры); RA: A×Tпд×R×PPn→Mп – правило выбора вычислительных процедур для решения задачи. С помощью системы TC проводится детальный анализ множества A с точки зрения дости- жения поставленных целей, затрат ресурсов, со- ответствия конкретным условиям реализации модели Mп и выбирается наилучший способ решения задачи поиска. Если установлено, что варианты решений, удовлетворяющие текущей цели, не могут быть получены за отведенное время, выбирается стратегия генерации приближенных вариантов решений. Шаг 2. Прогнозирование требуемого для поиска решения времени и параметров качества формируемых вариантов решений. Шаг 3. Определение, будет ли найдено решение за отведенное время и будут ли варианты решений удовлетворять заданным требованиям. Если ответ положительный, выполняется переход к шагу 4 (ветвь а на рис. 2). При невозможности удовлетворения временных ограничений T возникает необходимость применения аппроксимации или приближенных моделей и выполняется переход к шагу 5 (ветвь б на рис. 2).
В случае расхождения текущих и спрогнозированных значений осуществляется переход к шагу 3 (ветвь в на рис. 2). Шаг 5. Идентификация состояния процесса поиска и выбор (генерация) наиболее приемлемой аппроксимации его отдельных процессов, процедур и задач. Переход к шагу 2 (ветвь г на рис. 2). При переходе от использования полных моделей поиска решения к приближенным возможно применение различных типов аппроксимаций: 1) сокращенные модели всего процесса поиска и поиск решения не в полном объеме; 2) сокращенные модели отдельных процессов; 3) сокращенные (приближенные) способы выполнения отдельных процедур и решения отдельных задач. Существует большое количество подходов к выбору аппроксимаций, включающих: · применение традиционных (жестких) алгоритмов различной вычислительной сложности; · применение приближенных стратегий поиска (при использовании мягких средств, основанных на знаниях), позволяющих исследовать сокращенное пространство вариантов решений; · применение приближенных (обобщенных) данных, обеспечивающих более абстрактный взгляд на необходимые для учета при поиске решения факторы и позволяющих задействовать упрощенные пространства поиска решений и механизмы вычислений; · применение приближенных знаний, упрощающих применяемые в расчетных, логических и эвристических процедурах знания (например, посредством отказа от использования глубинных знаний и перехода к поверхностным знаниям), так что пространство поиска исследуется быстрее. Использование планировщика в ИСППР РВ для малого энергетического объекта При работе над прототипом ИСППР РВ для малого энергетического объекта был исследован и реализован набор аппроксимаций алгоритмов поиска решения, применимых в системах мониторинга и диагностики специфических энергетических объектов, например, малых ГЭС. Данная предметная область выбрана, во-первых, по причине относительно невысокой размерности пространства состояний системы в сравнении с более крупными объектами. Во-вторых, подобные системы достаточно инертны, что в большинстве случаев позволяет увеличить время поиска решения. С другой стороны, полезность данной системы сложно переоценить, так как в отличие от крупных энергетических объектов на малых гидростанциях персонал не имеет надлежащей квалификации и опыта для самостоятельного принятия наиболее эффективных решений в аномальных (нештатных) ситуациях. Параметры объекта, контролируемые системой, можно разбить по степени их значимости для оптимальной работы оборудования. Так, при выходе за допустимые пределы медленно изменяющихся параметров алгоритм располагает большим временем для выбора наилучшего управляющего воздействия. Для одних параметров важна предыстория развития, тогда как для других можно ограничиться только мгновенным значением. В результате исследования предметной области была разработана иерархия аппроксимаций, позволяющая оптимизировать работу системы. 1) Ap0 – безопасные действия. На данном уровне анализа состояния системы с помощью простой продукционной системы определяется набор действий, которые обеспечат гарантированный выход системы из аномального состояния. Применение таких действий приводит к существенному ухудшению полезности системы, защищая при этом оборудование от нештатных режимов работы. Профиль PP(Ap0) можно ограничить константой, зависящей от общего количества правил в продукционной системе. 2) Ap1 – диагностирование причин неполадки. С помощью экспертной системы, структурированной по определенным правилам, устанавливается набор причин возникновения неполадки, для найденных причин – набор эффективных действий для их устранения. В зависимости от времени, которым располагает данный алгоритм, исследуется различное пространство состояний. При увеличении времени, выделяемого планировщиком для работы Ap1, алгоритм поиска анализирует дополнительные условия (например, использование знаний о тенденции изменения значения параметра), переходит от использования интервальных оценок к лингвистическим переменным и аппарату нечетких логик. Профиль PP(Ap1) строится статистически на основе модели объекта М и симуляции возникающих неполадок. Качество возвращаемого решения определяется на этапе создания модели и корректируется на основе эмпирических данных. 3) Ap2 – прогнозирование последствий применения действия. Выполняются оценка результатов применения предварительно сформированного набора допустимых действий и выбор наилучшего на основе проведенного анализа. Анализ производится с помощью блока прогнозирования на основе модели М. Аналогично PP(Ap1) профиль PP(Ap2) строится статистически на базе модели системы и корректируется с помощью эмпирических данных. 4) Ap3 – использование накопленного опыта. Выбор действия основывается на накопленном опыте. Используя один из методов на основе накопленного опыта, например, подкрепленное обучение [3] или принятие решений на основе прецедентов [4], выбирается действие, максимизирующее возврат (платеж) среды. Предложенный алгоритм был апробирован на аналитических и имитационных моделях работы энергетического объекта типа малой ГЭС. Для оценки его эффективности были выбраны свойства своевременности, обоснованности и трудоемкости. Оценка показателей этих свойств проводилась для случаев реализации традиционных подходов и различных вариантов рассматриваемого способа решения задач. На основе полученных результатов можно сделать вывод, что предложенные методы позволяют осуществить поиск решения в ИСППР РВ за отведенное время с наилучшим возможным качеством. На базе проведенных исследований можно утверждать, что использование гибких алгоритмов, основанных на применении аппроксимаций на различных этапах принятия решения, позволяет оперировать с непрерывным пространством состояний и принимать решения с наилучшим возможным качеством в условиях жестких временных ограничений. В настоящее время на кафедре прикладной математики Московского энергетического института (технического университета) ведется работа по реализации данной системы с целью включения ее в базовые инструментальные средства конструирования ИСППР РВ для решения задач мониторинга и управления сложными техническими и организационными системами на примере объектов энергетики. Разработаны способы интеграции представленных выше методов в рамках единой системы, реализован обобщенный алгоритм планирования процесса поиска решения. Литература 1. Вагин В.Н., Еремеев А.П. Некоторые базовые принципы построения интеллектуальных систем поддержки принятия решений реального времени // Изв. РАН. Теория и системы управления. 2001. № 6. С. 114–123. 2. Еремеев А.П., Тихонов Д.А., Шутова П.В. Поддержка принятия решений в условиях неопределенности на основе немарковской модели // Там же. 2003. № 5. С. 75–88. 3. Еремеев А.П., Подогов И.Ю. Обобщенный метод иерархического подкрепленного обучения для интеллектуальных систем поддержки принятия решений // Программные продукты и системы. 2008. № 2. С. 35–39. 4. Вагин В.Н., Еремеев А.П. Исследования и разработки кафедры прикладной математики по конструированию интеллектуальных систем поддержки принятия решений на основе нетрадиционных логик // Вестник МЭИ. 2008. № 5. С. 16–26. 5. Котенко И.В. Модели и алгоритмы обеспечения гарантированного времени решения задач системами, основанными на знаниях // Междунар. конф. по мягким вычисл. и измерениям. SMC'2000: сб. докл. СПб: СПбГЭТУ, 2000. С. 254–257. 6. Boddy M., Dean T.L. Solving time-dependent planning problems // In Proceedings of the Eleventh International Joint Conference on Artificial Intelligence, Detroit, Michigan, 1989, рp. 979–984. 7. Hansen E., Zilberstein S. Monitoring the Progress of Anytime Problem-solving // In Proceedings of the 22st International Conference on Machine Learning, Portland, OR, 1996. |
 Основой для поиска решения являются эвристические методы, базирующиеся на учете специфики предметных/проблемных областей, знаниях и опыте специалистов-экспертов, решающих подобные задачи; собственно задача принятия решений, сформулированная как поиск в пространстве состояний или ситуаций, называется задачей эвристического поиска.
Основой для поиска решения являются эвристические методы, базирующиеся на учете специфики предметных/проблемных областей, знаниях и опыте специалистов-экспертов, решающих подобные задачи; собственно задача принятия решений, сформулированная как поиск в пространстве состояний или ситуаций, называется задачей эвристического поиска.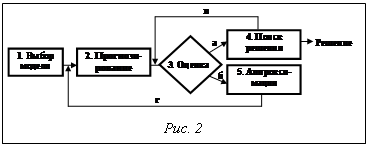 Шаг 4. Выполнение процесса поиска в соответствии с выбранной моделью M. Динамическое прогнозирование и отслеживание времени, требуемого для завершения процессов поиска, и показателей качества формируемых вариантов решений.
Шаг 4. Выполнение процесса поиска в соответствии с выбранной моделью M. Динамическое прогнозирование и отслеживание времени, требуемого для завершения процессов поиска, и показателей качества формируемых вариантов решений.| Permanent link: http://swsys.ru/index.php?id=2419&lang=en&page=article |
Print version Full issue in PDF (4.03Mb) Download the cover in PDF (1.25Мб) |
| The article was published in issue no. № 1, 2010 |
Perhaps, you might be interested in the following articles of similar topics:
- Прецедентный подход для оценки влияния молний на системы уличного освещения с использованием онтологий
- Абдуктивный вывод versus дедукция
- О реализации средств машинного обучения в интеллектуальных системах реального времени
- Становление и развитие научной школы искусственного интеллекта в Московском энергетическом институте
- Автоматизированная система поддержки принятия решений для прогнозирования процессов рассеивания химически опасных веществ
Back to the list of articles