Journal influence
Bookmark
Next issue
Formation and developing the scientific school of artificial intelligence in Moscow power engineering institute
The article was published in issue no. № 3, 2010Abstract:The basic stages in formation and developing the scientific school of artificial intelligence and intelligent systems in MPEI (TU) are considered.
Аннотация:Рассматриваются основные этапы становления и развития научной школы искусственного интеллекта и интеллектуальных систем в Московском энергетическом институте (техническом университете).
| Authors: Vagin V.N. (vagin@appmat.ru) - National Research University “MPEI”, Moscow, Russia, Ph.D, Eremeev, A.P. (eremeev@appmat.ru) - National Research University “MPEI” (Professor), Moscow, Russia, Ph.D, (eremeev@appmat.ru) - , Ph.D, (eremeev@appmat.ru) - , Ph.D, (eremeev@appmat.ru) - , Ph.D | |
| Keywords: decision making, intelligent systems, artificial intelligence |
|
| Page views: 18814 |
Print version Full issue in PDF (5.84Mb) Download the cover in PDF (1.43Мб) |
Московский энергетический институт (МЭИ) был образован в 1930 г. для обеспечения быстро растущих потребностей страны в высококвалифицированных кадрах в области энергетики и электротехники [1]. Активное развитие средств автоматики, АСУ и особенно вычислительной техники (ВТ) обусловило создание в МЭИ в 1958 г. факультета автоматики и вычислительной техники (с 2002 г. преобразованного в институт в составе МЭИ (ТУ)), включающего кафедры автоматики, вычислительной техники, системотехники и ряд других [2]. В 1958–1968 гг. на кафедре ВТ работал выдающийся ученый и педагог, крупнейший специалист в области информатики, кибернетики и искусственного интеллекта (ИИ), один из основателей направления «Искусственный интеллект» в СССР и Ассоциации искусственного интеллекта (сейчас Российская ассоциация искусственного интеллекта – РАИИ), первый главный редактор журнала «Новости искусственного интеллекта», издаваемого РАИИ с 1990 г. (с 2008 г. журнал стал называться «Искусственный интеллект и принятие решений», главный редактор – академик РАН С.В. Емельянов), действительный член РАЕН, лауреат премии Джона фон Неймана, доктор технических наук, профессор Дмитрий Александрович Поспелов. Д.А. Поспелов вместе со своими коллегами по кафедре, известными специалистами профессором В.А. Горбатовым (область интересов – кибернетика и логическое управление) и доцентом Е.Т. Семеновой (область интересов – языки ИИ и представления знаний), а также с первыми своими аспирантами, ставшими известными учеными в области ИИ и интеллектуальных систем (ИС), среди которых доктора наук Ю.И. Клыков и В.Н. Вагин, создали и развили такие направления в ИИ, как ситуационное управление, семиотическое моделирование, прикладная семиотика, системы распознавания и генерации текстов, которые на многие годы опередили аналогичные западные разработки и остаются чрезвычайно актуальными в настоящее время. 1970-е годы – время становления научной школы МЭИ в области ИИ, основы которой заложены Д.А. Поспеловым. Тогда под руководством Е.Т. Семеновой начались работы по реализации трансляторов с популярных языков ИИ LISP и APL, которые в конце 70-х – начале 80-х годов были внедрены на ЭВМ серии ЕС. На основе языка LISP/ЕС был разработан ряд медицинских и диагностических интеллектуальных (экспертных) систем, систем распознавания текстов и принятия решений. С появлением и массовым использованием персональных компьютеров в 80-е годы уже на кафедре прикладной математики (ПМ) основные усилия научной группы Е.Т. Семеновой были направлены на разработку программного обеспечения под новую техническую базу. Была создана система MFRL/PC – первая в СССР реализация языка ИИ FRL (Frame Representation Language), ориентированная на представление и обработку сложноорганизованных и структурированных глубинных знаний на основе фреймов. Возможность представления и оперирования глубинными, а не только поверхностными, слабоструктурированными знаниями позволила эффективно заниматься такими нетривиальными проблемами ИИ, как распознавание слитной речи, сочинение музыки, игра в шахматы и другими. В 1976 г. из кафедры ВТ выделилась кафедра ПМ, куда перешли многие специалисты в области ИИ и конструирования ИС – соратники, ученики и ученики учеников Д.А. Поспелова. В 1992 г., будучи руководителем отдела ВЦ РАН, Д.А. Поспелов вернулся в МЭИ на кафедру ПМ совместителем и проработал на ней до 1998 г. (его уход из МЭИ и ВЦ РАН был связан с тяжелой болезнью). К этому времени на кафедре сложился сильный коллектив специалистов в области ИИ и ИС, руководимый учеником и ближайшим соратником Д.А. Поспелова профессором В.Н. Вагиным. Дмитрий Александрович стал лидером коллектива, активизировав исследования по ряду новых направлений ИИ, в частности, в области прикладной семиотики и применения нетрадиционных логик в ИС семиотического типа [3]. Была создана научная лаборатория по прикладной семиотике. Работа коллектива в данном направлении освещена в многочисленных статьях, опубликованных в журналах «Новости искусственного интеллекта», «Известия АН СССР. Техническая кибернетика» и «Известия РАН. Теория и системы управления», «Программные продукты и системы», «Искусственный интеллект и принятие решений», «Вестник МЭИ» и др., в материалах российских и международных конференций по проблемам ИИ и конструирования ИС (см., например, [4–11]). Огромная эрудиция и талант Д.А. Поспелова привлекали к нему как начинающих, так и известных специалистов. При его непосредственном участии на кафедре ПМ было организовано обучение студентов по специализации «искусственный интеллект и интеллектуальные системы», он поставил курсы «Основы искусственного интеллекта» и «Прикладная семиотика». Его увлекательные, яркие лекции захватывали студентов, неизменно собирая полные аудитории.
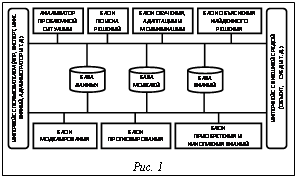
Исследования и разработки методов и инструментальных программных средств конструирования ИСППР В МЭИ (ТУ) на базе кафедры ПМ успешно функционирует созданная Д.А. Поспеловым научная школа. Руководят ею лауреаты премии Президента РФ в области образования, доктора наук, профессора, действительные члены РАЕН и члены Научного совета РАИИ В.Н. Вагин, А.П. Еремеев, В.П. Кутепов. Исследования, проводимые на кафедре, связаны с теоретическими и прикладными вопросами ИИ, вопросами создания математического и программного обеспечения ИС поддержки принятия решений (ИСППР) для мониторинга и управления сложными техническими объектами, интеллектуальных тренажерных систем и систем организационного управления с применением нетрадиционных логик, распределенной и параллельной обработки информации, сетевых технологий. По данной тематике выполняется ряд проектов по постановлениям Правительства РФ и грантам РФФИ, ежегодно обучается около 20 аспирантов, защищаются докторские и кандидатские диссертации. Многие студенты, аспиранты и ученые кафедры награждены дипломами и премиями РАИИ, дипломами различных конкурсов, удостоены грантов, включая международные, за научно-исследовательские работы по тематике ИИ. В 2000 г. авторский коллектив ученых и специалистов МЭИ (ТУ) (головной вуз), МГТУ им. Н.Э. Баумана, МИФИ, МЭСИ, РосНИИ ИТ и АП, среди которых были три представителя кафедры ПМ – В.Н. Вагин (руководитель коллектива), А.П. Еремеев, В.П. Кутепов, удостоены премии Президента Российской Федерации в области образования за создание и внедрение учебно-методического комплекса «Методы, модели и программные средства конструирования интеллектуальных систем принятия решений и управления» для вузов. Остановимся на исследованиях, выполняемых на кафедре по тематике разработки базовых инструментальных средств конструирования ИСППР, в том числе ИСППР реального времени (ИСППР РВ) на основе нетрадиционных логик (индуктивных, абдуктивных, темпоральных и т.д.), на основе аналогий и прецедентов [5, 6, 8–14]. Обобщенная архитектура ИСППР РВ показана на рисунке 1. ИСППР РВ является системой распределенного интеллекта и состоит из взаимодействующих между собой интеллектуальных блоков (модулей), выполняющих различные интеллектуальные функции. К числу таких блоков, помимо традиционных для ИС баз данных и знаний, блоков поиска решения, приобретения и накопления знаний, объяснения и т.д., относятся блоки моделирования проблемной ситуации, обучения, прогнозирования, связи с внешними объектами (датчиками, контроллерами, концентраторами данных, управляющими приводами и т.д.), средства организации различного типа интерфейсов (образного, текстового, речевого, в виде графиков и диаграмм и т.д.) с пользователями (ЛПР, экспертом, инженером в области знаний). К интеллектуальным относятся функции поиска (вывода) решения на базе моделей и методов представления и оперирования динамическими знаниями, характеризующимися различного типа неопределенностями (так называемыми НЕ-факторами - неточностью, нечеткостью, недостоверностью, неполнотой, противоречивостью и т.д.). Поиск решения осуществляется с использованием механизмов эвристического поиска, методов нетрадиционных логик и методов обучения. Ранее отмечалась перспективность конструирования современных ИС типа ИСППР РВ, ориентированных на открытые и динамические предметные (проблемные) области, на основе предложенной Д.А. Поспеловым концепции семиотической системы [3].
Каждая из моделей системы ориентирована на обработку некоторого типа неопределенности (НЕ-фактора) или некоторой их совокупности. Концепция использования интегрированной среды, включающей различные модели и методы поиска решения в условиях различного рода НЕ-факторов, реализуется в прототипе ИСППР РВ семиотического типа для управления сложными объектами и процессами типа энергоблока [9–12]. В плане исследования и разработки методов и базовых инструментальных средств конструирования ИСППР, включая ИСППР РВ, семиотического типа на основе нетрадиционных логик получен ряд фундаментальных результатов. Остановимся на основных из них. Разработан обобщенный алгоритм поиска решения на основе структурной аналогии свойств и отношений, который в зависимости от исходных данных и времени, выделяемого на поиск решения, реализует различные схемы рассуждения на базе аналогий, использующие как аналогию свойств, так и аналогию отношений. Если источник для аналогии не задан, этап определения потенциальных аналогов реализуется с помощью алгоритмов поиска решения на основе структурной аналогии свойств, а затем к полученным аналогиям применяется алгоритм поиска решения на основе структурной аналогии отношений. Предложенный обобщенный алгоритм обеспечивает обнаружение потенциальных аналогов и при отсутствии данных для определения первоначального контекста. Для успешной реализации механизмов умозаключений на основе аналогий и прецедентов в ИСППР РВ необходима соответствующая система поиска решения, интегрирующая в себе данные механизмы умозаключений. Главная цель использования прецедентов заключается в выдаче готового решения оператору (ЛПР) для текущей ситуации на основе прецедентов, которые уже имели место в прошлом при управлении данным объектом или системой. На рисунке 2 представлена организация цикла рассуждений на основе прецедентов (CBR-цикла (Case-Based Reasoning)) [9]. Основными этапами CBR-цикла являются: − извлечение из библиотеки прецедентов наиболее соответствующего (подобного) для сложившейся ситуации прецедента; − повторное использование извлеченного прецедента для попытки решения текущей проблемы; − пересмотр и адаптация в случае необходимости полученного решения соответственно текущей проблеме; − сохранение вновь принятого решения как части нового прецедента; − применение эвристик, повышающих эффективность решения задач. В среде визуального программирования Borland C++ Builder разработана система поиска решения на основе аналогий и прецедентов, в которой предусмотрено взаимодействие двух основных компонентов – конструктора библиотеки прецедентов, реализующего механизм рассуждения на основе прецедентов, и редактора семантических сетей, реализующего механизм поиска решения на основе структурной аналогии. Данная система использована в прототипе ИСППР РВ для решения задачи диагностики состояний сложного технического объекта и выдачи управляющих воздействий для одной из подсистем реактора типа ВВЭР. Исследованы модели и методы представления темпоральных (временных) зависимостей, составлена их развернутая классификация с учетом способа представления информации о времени, выразительных способностей и алгоритмической сложности. Разработан язык представления временных зависимостей, ориентированный на использование основных моделей (алгебр временных отношений) – точечной, интервально-точечной и интервальной. Проанализированы и разработаны методы решения основных задач согласования временных ограничений (ЗСВО), что позволило на базе единого внутреннего представления выполнить программную реализацию алгоритмов вывода. Разработаны и реализованы перспективные алгоритмы пошагового решения ЗСВО для ИСППР РВ, ориентированной на работу с открытыми и динамическими предметными областями. Данные алгоритмы имеют существенное преимущество перед известными статическими алгоритмами, требующими полного повторного решения ЗСВО после каждой модификации. На языке С# в среде ОС Windows реализована система временных рассуждений (СВР) для точечной, точечно-интервальной и интервальной моделей времени. Выполнена реализация СВР также в среде ОС Unix на языке С++ в плане ее использования на параллельных и распределенных (кластерных) вычислительных системах. Разработаны средства для интеграции СВР с базовой средой конструирования интеллектуальных систем CLIPS, позволяющие использовать СВР совместно с широко применимой продукционной моделью представления знаний. Реализован многофункциональный редактор сетей временных ограничений, позволяющий в наглядной форме создавать, верифицировать и редактировать различные временные зависимости. Исследованы различные методы подкрепленного обучения (RL – Reinforcement Learning) в контексте использования их в составе ИСППР РВ в условиях неопределенности, жестких временных ограничений и сложных динамических сред. Среди известных методов были выбраны обладающие высокой скоростью обучения, эффективно использующие память, имеющие возможность работать с непрерывными пространствами ощущений. Рассмотрены возможности повышения качества и скорости обучения. В частности, предложены методы на основе оценочной функции с памятью ограниченного объема, что позволяет оперативно принимать решения и быстро адаптироваться к изменяющемуся поведению среды, а также методы иерархического подкрепленного обучения, дающие возможность решать задачи большой размерности и задачи, включающие этапы, требующие отдельного обучения. Отметим, что RL-обучение – перспективный подход для программирования агентов в мульти- агентных системах (МАС), позволяющий найти оптимальную стратегию действий (поиска решения) даже тогда, когда практически отсутствует информация о среде, в которой должен функционировать агент. На основе эволюционной теории игр были разработаны алгоритмы для решения задачи RL-обучения для МАС и для специального случая, когда стратегии оппонентов нестационарные, но имеют предел. Доказана сходимость предложенных алгоритмов для стохастических марковских игр. Реализованы основные блоки системы RL-обучения на основе предложенных методов, и расширена существующая среда моделирования процессов и управления обучаемыми агентами за счет добавления средств иерархического обучения и обучения с учителем. Для описания задач RL-обучения на основе формализма частично обозримых марковских процессов принятия решений разработан язык, позволяющий описывать систему или объект управления посредством множества параметров различного типа (целый, вещественный, логический, описательный), их взаимодействия с учетом времени, а также действий агента над средой и выплат, получаемых агентом при выполнении того или иного действия. Предложенный язык позволяет описывать также системы с множеством агентов, которым доступны различные действия и сенсоры, а также переключаться между ними в процессе принятия решения. Программный комплекс RL-обучения реализован на языке C++ в среде Microsoft Visual C++ 7.0. Исследованы основные виды параллелизма в дедуктивном выводе: на уровне термов, на уровне дизъюнктов, на уровне поиска. Разработаны алгоритмы параллельной унификации и параллельного вывода на графе связей Ковальского. Реализованы алгоритмы для различных типов параллельного вывода (OR-, AND- и DCDP) на графе связей. Создан программный комплекс системы параллельного вывода PIS (Parallel Inference System) на графе связей. Исследованы различные системы аргументации и получены результаты их сравнительного анализа. Теорию аргументации можно рассматривать как средство реализации абдуктивного вывода, позволяющего определить наилучшее абдуктивное объяснение как выигравшее в ходе определения статуса множеств гипотез-аргументов по правилам конкретной семантики при заданном отношении поражения. Реализован эффективный алгоритм поиска абдуктивных объяснений для случая, когда теория представлена логической программой, а объяснение – множеством гипотез-умолчаний (предикатов с отрицанием по умолчанию). Объяснения могут быть получены в аргументационной семантике допустимости, приемлемости и в фундированной семантике. В настоящее время исследуется задача, определяющая случаи, в которых следует отдать предпочтение той или иной аргументационной семантике, и свойства полученных объяснений. Исследованы возможности расширения аппарата таблиц решений (ТР) в плане применения в ИСППР РВ. В качестве базовой модели рассмотрены ТР с расширенным входом (ТРВ), которые исследованы существенно слабее, чем широко используемые ТР с ограниченным входом (ТОВ). Исследованы средства задания метазнаний в виде отношений между условиями в табличных моделях, методы обработки ТРВ с темпоральной информацией, методы представления и реорганизации наборов связанных таблиц. Специфика предметной области, как правило, накладывает ограничения на взаимное сочетание значений условий, учитываемых в таблицах. Тем самым из множества синтаксически возможных состояний предметной области (множества входных векторов) выделяется область семантически допустимых состояний. Для формального описания области допустимых (а также запрещенных) состояний удобно задавать ограничения на значения условий в явном виде, вводя логические отношения между условиями в ТР. Процедуры обработки таких зависимостей включают выявление зависимостей между условиями в заданной ТР, проверку ТР на соответствие заданным зависимостям, построение расширенной таблицы при проверке корректности ТР и контроль множества входных векторов при принятии решений по ТР. Предложены алгоритмы обработки зависимостей между условиями в ТРВ с применением аппарата приближенных множеств, расширенного средствами оперирования нечеткими множествами. Введены пропозициональные логические отношения импликативного вида над термами с условиями, которые используются при проверке табличной модели на согласованность правил с заданным набором отношений. Правила, применимые к запрещенным входным векторам, удаляются из модели. В случае обобщенного правила оно может быть скорректировано (включая его редукцию на ряд простых правил) для распознавания только семантически допустимых входных векторов. Перспективным вариантом развития табличных моделей является введение временной информации в структуру ТР. Примером такой интегрированной модели являются таймированные ТР. При этом базовая структура ТР расширяется таблицей зависимостей, определяющей возможности последовательного или параллельного выполнения действий, содержащихся в основной ТР, и таблицей задержек, используемой для моделирования длительности выполнения действий. Проанализированы различные типы связей между ТР: передача контекста для принятия решения, вызов подтаблицы-условия (аналог вызова функции в процедурных языках) и вызов подтаблицы-действия (аналог вызова процедуры). На основе полученных результатов на языке C++ в интегрированной инструментальной среде Microsoft Visual Studio 2005 разработаны базовые модули новой версии системы моделирования принятия решений СИМПР-Windows, расширенной средствами обработки ТРВ. Исследованы возможности реализации планировщика для поиска решения с применением параллельных и распределенных вычислительных систем (на примере SMP-систем с общей памятью). Реализован параллельный алгоритм эвристического поиска на языке C с использованием библиотеки OpenMP версии 2.5. Проведены вычислительные эксперименты в режиме моделирования параллельных вычислений на кластере на основе двухъядерных процессоров Intel Core Duo с использованием средств отладки Intel Thread Profiler 3.0. Выполнена интеграция разработанного планировщика в ИСППР РВ для решения задачи оперативного мониторинга и анализа разнородной информации. Планировщик является основой модуля оперативного поиска решения, выполняющего следующие функции: поиск пути от исходного объекта до целевого по дереву связей; поиск объектов, связанных с исходным объектом или группой объектов заданными отношениями; поиск цепочек связей для нахождения прямых и опосредованных связей заданной глубины между объектами и группами объектов. Исследованы принципы диагностирования устройств на основе моделей функционирования. Предложен перспективный подход, в основе которого лежат прогнозирование предполагаемого поведения устройства исходя из имеющейся в наличии информации, а также обнаружение различий прогнозов с реальным поведением и объяснение причин данных различий (список неисправных компонентов), что позволяет одинаково успешно находить как одиночные, так и множественные неисправности, диагностировать устройства при отсутствии экспертных данных о причинах всевозможных неисправностей, многократно использовать готовые описания моделей функционирования для других устройств и получать детальные объяснения причин выявленных неисправностей. В контексте данного подхода произведено исследование систем поддержки истинности (СПИ), в частности СПИ, основанных на предположениях, главным достоинством которых является возможность работы в нескольких контекстах, что позволяет одновременно строить множество вариантов прогнозов для задач диагностики на основе модели функционирования устройства и без дополнительных ресурсов отвергать те прогнозы, которые по каким-либо причинам не подошли. СПИ, основанная на предположениях, выбрана в качестве платформы для построения комплекса диагностирования на основе моделей функционирования. На базе такой СПИ разработаны три типа подходов к нахождению наилучшего места снятия показаний в диагностике на основе модели функционирования: эвристический подход на базе выведенных прогнозов и знаний о поддерживающих и противоречивых окружениях; вероятностный подход, базирующийся на использовании априорной вероятности работоспособности компонентов системы и использующий структурную зависимость между компонентами устройства с учетом истории процесса диагностики; комбинированный подход на основе вероятностного метода с использованием эвристики проверки работоспособности конкретных компонентов. При сравнительном анализе по критериям эффективности выбора наилучшего места снятия показаний и затрат временных ресурсов в процессе диагностики неисправности устройств выявлено, что наилучшим является комбинированный метод, соединяющий в себе вероятностный и эвристический подходы. Разработаны алгоритмы и на их основе прототип СПИ для ИСППР РВ, осуществляющей прогнозирование работы объекта исходя из измеренных значений входов и выходов его компонентов с учетом предположений об их исправности. Разработана многоуровневая архитектура многоагентного диагностического комплекса. На самом нижнем уровне находятся агенты наблюдения за устройством, обеспечивающие снятие показаний с диагностируемого устройства. Уровнем выше – агенты диагностики, обрабатывающие получаемую информацию с целью разрешения противоречий, обнаруженных при сравнении прогнозов поведения компонентов устройства с результатами снятых показаний. Над ними – агенты управления группами агентов диагностики, которые объединяют получаемые сведения и строят целостную картину о состоянии устройства, диагностируемого связанными с ним агентами диагностики. Когда для одной и той же точки устройства прогнозы построены несколькими диагностическими агентами, решается проблема сведения этой информации воедино. На самом верхнем уровне находится агент общего управления, который вводится при использовании нескольких агентов управления агентами диагностики. Агент общего управления осуществляет взаимодействие между агентами управления группами, согласует и объединяет всю информацию о состоянии диагностируемого устройства. После активизации каждый из агентов автономен и действует, исходя из своей цели, имеющейся в наличии информации и сообщений, получаемых из внешней среды, от других агентов или от ЛПР. Установлено, что применение многоагентного подхода (МАС) позволяет повысить эффективность диагностического комплекса на базе СПИ, благодаря снижению затрат временных и программных ресурсов за счет распараллеливания работы агентов. Известно, что одним из наиболее используемых критериев эффективности методов поиска решения на основе знаний в ИСППР РВ является критерий достижения наилучшего качества вырабатываемых вариантов решений за отведенное время. Решение, найденное несвоевременно, обычно не имеет практической пользы. Поэтому принимаемое решение, во-первых, должно быть наилучшим среди возможных альтернатив, а во-вторых, принято своевременно, то есть процесс его поиска должен удовлетворять некоторым временным ограничениям T. Строгие алгоритмы оптимизации могут искать точное решение задачи в течение достаточно долгого времени, не удовлетворяющего заданным ограничениям T. Однако зачастую достаточно хорошее и приемлемое приближенное решение может быть найдено за значительно более короткое время. В ИСППР РВ предлагается использовать для поиска решения так называемые гибкие (anytime) алгоритмы, характеризующиеся тем, что качество получаемых результатов улучшается с увеличением времени работы алгоритма. Гибкие алгоритмы можно выполнять либо с заранее предусмотренным лимитом времени выполнения, либо с возможностью останова в любой момент. Эти алгоритмы можно вновь активизировать после того, как они были остановлены по истечении лимита времени или из-за прерывания, и продолжить поиск более лучшего решения. При разработке прототипа ИСППР РВ для мониторинга и диагностики энергетического объекта малой ГЭС был реализован и исследован набор гибких алгоритмов поиска решения. Целесообразность внедрения ИСППР РВ именно на малых ГЭС обусловлена тем, что в отличие от крупных энергетических объектов оперативно-диспетчерский персонал (ЛПР) малой ГЭС не имеет надлежащей квалификации и опыта для самостоятельного принятия наиболее эффективных решений в сложных нештатных ситуациях. Результаты моделирования показали, что предложенные модели и алгоритмы позволяют осуществить поиск решения за отведенное время с наилучшим возможным качеством. Отдельно остановимся на исследованиях по проблеме обобщения информации при наличии зашумленных данных, которые проводятся в МЭИ совместно кафедрами ПМ и ВТ [6, 13, 14]. Интерес пользователей к средствам интеллектуального анализа данных и обнаружения знаний в БД (KDD – Knowledge Discovery in Databases) существенно возрастает. Извлечение знаний является средством для обнаружения стратегической информации, скрытой в больших БД, формирования неких шаблонов, которые можно применять в будущем при возникновении схожих ситуаций. KDD-системы имеют возможность перерабатывать и анализировать сырые данные, предоставляя извлеченную информацию скорее и успешнее, чем аналитик. Область применения KDD-систем не ограничивается только сферой бизнеса. Они успешно применяются в медицине для постановки диагноза, в фармакологии для прогнозирования свойств новых лекарств, для решения различных экономических задач и т.д. Обнаружение знаний в БД представляет собой многоэтапный процесс нахождения новых важных, потенциально полезных и понятных пользователю зависимостей в данных. Цель KDD-систем – обобщить известные данные, основанные на фактах и наблюдениях, и затем, используя сформированные знания в виде решающих правил, решить необходимую задачу (классификации, кластеризации, прогнозирования и др.). Обнаружение знаний в БД тесно связано с решением задачи индуктивного формирования понятий, или задачи обобщения [6]. Сформулируем задачу обобщения понятий по признакам. Пусть O={o1, o2, …, on} – множество объектов, которые могут быть представлены в интеллектуальной системе S. Каждый объект oiÎO, 1£i£n, представляется как множество значений признаков, то есть oi={xi1, xi2, …, xir}, где r – количество признаков объекта. Могут использоваться количественные, качественные либо шкалированные признаки объектов. В основе процесса обобщения лежат сравнение описаний исходных объектов, заданных совокупностью значений признаков, и выделение наиболее характерных фрагментов этих описаний. В зависимости от того, входит или не входит объект в объем некоторого понятия, назовем его положительным или отрицательным объектом для этого понятия. Среди множества всех объектов O выделим V – подмножество положительных объектов некоторого понятия и W – подмножество отрицательных объектов. Рассмотрим случай, когда O=VÈW, VÇW=Æ. Пусть K – непустое множество объектов, такое, что K=K+ÈK–, где K+ÌV и K–ÌW. Множество K является обучающей выборкой, на основании которой надо построить правило, разделяющее положительные и отрицательные объекты обучающей выборки. Если удалось построить такое решающее правило, которое для любого примера из обучающей выборки указывает, принадлежит этот пример понятию или нет, то понятие сформировано. Решающее правило является корректным, если в дальнейшем оно успешно распознает объекты, первоначально не вошедшие в обучающую выборку. Известен ряд методов для решения поставленной задачи. Методы, обычно используемые для извлечения полезной информации из данных, можно разделить на следующие группы: статистические методы, индуктивный вывод и вывод, основанный на прецедентах, нейронные сети, деревья решений, байесовские сети доверия, генетические алгоритмы и эволюционное программирование, приближенные множества. Одна из проблем, возникающих при работе с реальными массивами данных, связана с наличием неточных, неполных, противоречивых данных, называемых шумом. Понятие «шум» включает в себя различные искажения (НЕ-факторы), которые могут присутствовать в исходных данных. Шум возникает по таким причинам, как некорректное измерение входного параметра, неверное описание параметра экспертом, использование дефектных измерительных приборов, потеря данных при пересылке и хранении информации. В таких случаях значения признаков объектов, используемых в качестве обучающей выборки, могут быть искажены или вообще отсутствовать. Наличие зашумленных данных изменяет приведенную постановку задачи как на этапе построения обучающих правил, так и на этапе классификации объектов, поскольку исходная обучающая выборка K заменяется на выборку K', в которой с некой вероятностью встречаются искаженные значения атрибутов. Исследование влияния шума на работу алгоритмов обобщения было выполнено на основе сравнительного анализа ряда известных алгоритмов обобщения (ID3, С 4.5, СN2 и др.), а также алгоритмов на основе приближенных множеств и их модификаций. Данные алгоритмы относятся к алгоритмам обучения с учителем: первоначально на обучающей выборке формируются классификационные правила, затем на контрольной выборке проводится экзамен, результаты которого позволяют оценить эффективность проведенного обобщения. В основе предложенных модификаций алгоритмов – введение процедур, как снижающих влияние шума при получении обобщенных понятий, так и уменьшающих ошибки классификации. Экспериментальные исследования подтвердили способность модифицированных алгоритмов эффективно обрабатывать зашумленные данные при наличии шума различных типов (НЕ-факторов). Развитие направления «Открытые интеллектуальные системы»: создание методов и инструментальных средств поискового проектирования На кафедре вычислительных машин, систем и сетей (ВМСиС) под руководством профессора И.И. Дзегеленка ведутся разработки методов и инструментальных средств поискового проектирования в рамках направления «Открытые интеллектуальные системы (ОИС)». Это достаточно молодое направление в ИИ, получающее все большее признание в образовании и науке [15–17]. Оно предусматривает создание усилителей искусственного разума, обладающих чертами творческой личности, такими как любознательность в постижении свойств окружающего мира, парадоксальность выдвигаемых гипотез, распределенность растущей базы знаний, надежность индуктивного вывода и немонотонность формируемого знания в целом при добавлении новых предметных переменных. Начало официальному признанию этого направления положено работами профессора Карла Хьюитта (Массачусетский технологический институт, США), создателя языка ПЛЭННЕР – одного из первых языков ИИ. Выдвинутая им в конце прошлого века концепция ОИС рассматривается в виде интеллектуальной компьютерной среды, обладающей рядом отмеченных выше свойств. Однако столь широкое толкование ОИС не позволяет выразить феноменальные способности творческой личности достаточно глубоко и во всей полноте. Необходимы строгие формальные уточнения и построения. Особого внимания заслуживает научная школа Д.А. Поспелова, работающая в этом направлении. Достаточно отметить выполненные непосредственно под его руководством такие разработки, как логико-лингвистические модели, наделенные способностью по- полнения и обобщения знаний, ситуационное управление, предусматривающее пополнение недостающих знаний. К этим работам примыкают исследования учеников Д.А. Поспелова в части создания МАС совместного добывания знаний, систем машинного обучения, в том числе обучения по прецедентам, исследования по развитию темпоральных логик и т.д. Приведем разработки, которые выполнены во многом под конструктивным влиянием школы Д.А. Поспелова, по уровню формальных построений приближающей нас к практическому осуществлению ОИС. Искомое знание будем представлять в виде некоторой закономерности профессионального успеха g(x1, …, хn) относительно варьируемых переменных xi, i= Сложность построения такой модели обусловливается наличием уже упоминавшихся НЕ-факторов при описании плохо формализуемых задач, типичными представителями которых являются задачи поискового проектирования. Построению модели препятствуют, по меньшей мере, следующие НЕ-факторы: неопределенность цели, неаналитичность предъявляемых требований-ограничений, недостаточность системного видения рассматриваемых свойств в виде определяемых предметных переменных, немонотонность в сохранении качественных оценок при введении новых предметных переменных, нереализуемость ряда комбинаций при вариации значений предметных переменных, неполнота фактов, представляющих искомую модель, нелинейность выявляемого знания в целом. Необходимость преодоления столь серьезных НЕ-факторов указывает на то, что, если и существует возможность формализованного построения искомой модели, то она должна быть многоэтапной в осуществлении целенаправленного диалога человека с машиной. Можно говорить лишь о частичной автоматизации этого процесса. Пальма первенства принадлежит человеку. Главное – выработать методологию открытия нового, которая должна носить познавательный характер. Определение открытой задачи поискового проектирования. Пусть зафиксирован набор внутренних параметров pi, i= Полагая, что порядок задаваемых имен зафиксирован по индексу j, каждую переменную xi можно рассматривать как именную переменную, принимающую соответствующие именные значения j= Не исключено, что свободно определяемое поисковое пространство Dn противоречиво, то есть существуют такие I-запрещенные комбинации значений порядковых переменных xi, которые определяют множество Фзапр запрещенных фигур (не имеющих физического смысла альтернатив) xÌФзапр ÍV, где V=M1´ ... ´Mn, тогда W=V\Фзапр – множество допустимых решений. Пусть далее существует следующий способ свободного задания цели. Предлагается ограничиться лишь вынесением качественных оценок об альтернативах x с помощью некоторого правила-предиката Q(x), имеющего только две градации: Q(x)=1, если x признается как удачное решение, и Q(x)=0 в противном случае. Здесь и далее через T обозначим множество удачных, а через F – неудачных решений. Если же принято соглашение об оценке x с помощью набора внешних показателей качества fl(x)àmin, то для определения области истинности предиката Q(x) можно ограничиться заданием набора граничных значений flo, где l= Следует отметить ограниченность текущих сведений об удачах и неудачах, что можно выразить заданием соответствующих множеств: T(u)ÌT, F(u) ÌF, где u – порядковый номер сеанса приобретения эмпирических знаний. Таким образом, список определяет текущую базу фактов Ex(u) (от англ. example). Индуктивное обобщение последних составляет основу для получения приближений g(u)(x) к искомой закономерности удачи g(x). Однако на практике приходится считаться с тем, что обычно |T(1)|<<|T|, |F(1)|<<|F| и потому 1-е приближение g(1)(x) может оказаться слишком далеким от истины. Следовательно, нужен некоторый механизм целенаправленного пополнения фактов. Представим его в виде оператора Pà{x0}, где x0 – эмпирические гипотезы о достоверности g(u)(x), требующие экспериментальной проверки. Открытая задача поискового проектирования – это конструкция , действие которой направлено на восстановление искомой модели-закономерности удачи g(x) на всей области значений порядковых переменных в поисковом пространстве Dn (с учетом запрещенных комбинаций I) в результате многократного (u=1, ..., U) обобщения активно пополняемой базы фактов Ex(u), образуемой путем целенаправленного выдвижения эмпирических гипотез x0 и их качественной оценки по правилу Q(x0). Данное определение отражает суть предлагаемого подхода, который позволяет в свободной форме на лету методически единообразно ставить и решать открытые задачи по выявлению недостающего эмпирического знания, не прибегая к построению и применению трудноуловимых и во многом неадекватных аналитических моделей. Нужно лишь подчеркнуть следующее. Разрешимость открытых задач постулируется следующим свойством представительности. В поисковом пространстве Dn существуют такие наиболее информативные множества T0, F0 опорных решений x0 Î{T,F}, которые достаточно полно представляют множества T, F и границу их разбиения g(x)=0, такую, что g(x)³0, если xÎT; g(x)<0, если xÎF. Данное свойство, определяемое и воспринимаемое как постулат, хорошо согласуется с представлением о существовании внутреннего порядка в виде «островов» и «архипелагов», а точнее – многомерных многообразий удачных решений в поисковом пространстве Dn. Только тогда можно говорить о существовании именно закономерности удачи в классе {g(x)}, обладающей панорамным видением всех решений, и только тогда обнаруженный порядок может оказать влияние на степень сокращения числа эмпирических гипотез x0 в практически неограниченной области W\Ex(u). Постановка открытой задачи является первым и наиболее важным этапом решения, от которого зависит конечный успех выявления скрытого знания. Именно на этом этапе в наибольшей степени проявляются творческий характер решаемых задач и талант проектировщика. Заметим, что подавляющее большинство объектов удобно описывать булевыми переменными xijÎ{0,1} с двойной индексацией, где i – номер параметра, j – номер его именного значения. Тогда представляющее интерес знание или закономерность удачи g(x) можно отобразить в виде обобщенной скалярной функции выбора с весовыми коэффициентами сij при каждой переменной xij нелинейной компонентой Z сколь угодно высокого порядка и порогом c0: Преимущество представления искомого знания в виде обобщенной скалярной функции выбора g(x) заключается в возможности достижения эффекта приоритетного различения альтернатив-решений: xα лучше xβ, если только g(xα)>g(xβ). С точки зрения достижимости некоторой обобщенной цели, заложенной в определяемое правило Q(x), такая возможность не возникает из ничего. Она является результатом выявления островов удачи, существование которых постулируется свойством представительности. Продолжением этого рассуждения является нахождение наилучшего решения x*=Arg maxxg(x) среди xÎТ, которое можно трактовать как открытие, если окажется, что x*ÏТ(1). Для синтеза искомого знания g(x) нужна информация об опорных множествах T0, F0. Но их нахождение возможно лишь при наличии уже синтезированной функции g(x). Для выхода из, казалось бы, заколдованного круга предлагается следующая стратегия. В общем случае u-й уровень знаний индуктивно обобщается в виде приближения g(u)(x) к искомой функции выбора. Для этого решается открытая к пополнению система неравенств: g(x)>0 для всех xÎT(u) и g(x)<-1 для всех xÎF(u). Не исключено, что текущее приближение к искомому знанию далеко от совершенства. Для выявления противоречий относительно g(u)(x) порождаются эмпирические гипотезы, определяемые в виде опорных решений двух сортов: положительные гипотезы x0+ÎS0(u), для которых g(u)(x0+)³0, и отрицательные гипотезы x0--ÎE0(u), когда g(u)(x0–)<0. Механизм и, соответственно, метод выдвижения гипотез строго формализованы. В основе их выдвижения лежит критерий топологической полноты обследуемых подпространств. В первом приближении – это точки x0, находящиеся вблизи гиперповерхности g(u)(x)=0. Полученные таким образом гипотезы подвергаются качественной оценке с применением правила Q(x). Если окажется, что все x0+ÎT и все x0–ÎF, то есть все гипотезы полностью подтвердятся по знаку, то g(u)(x) – искомое знание. Однако на начальных стадиях u=1, 2 ,… индуктивного обобщения фактов обнаруживаются противоречия, то есть часть решений x0+ÎF, а часть решений x0–ÎT, и потому искомое знание недостоверно. Тогда выявленные противоречия автоматически превращаются в факты в виде соответствующих множеств-пополнений: DF(u)={x0+ÎF}, DT(u)= ={x0–ÎT}, что позволяет индуктивно перейти на следующий (u+1) уровень знаний. Описанный процесс порождения и качественной оценки эмпирических гипотез многократно повторяется. Критерием остановки итеративного процесса служит отсутствие новых гипотез. Сами же гипотезы выдвигаются по критерию полноты тестирования искомого знания или закономерности удачи. Геометрически эта закономерность представляет границу разделения всего мира объектов (а не его части в виде начальной базы факторов) на удачи и неудачи. Стратегия выдвижения гипотез основана на выявлении, прощупывании только этой границы, а не всего поискового пространства. В результате резко сокращается число выдвигаемых гипотез или вопросов к эксперту при одновременном повышении достоверности искомого знания. Практическая польза от применения предлагаемой стратегии заключается в следующем. Во-первых, она направлена на выявление как можно большего числа противоречий для функции выбора. Это означает, что g(u+1)(x) не может быть хуже g(u)(x). Во-вторых, при благоприятном стечении обстоятельств (многократное подтверждение гипотез) обеспечивается резкое сокращение числа рассматриваемых альтернатив по сравнению с полным перебором. Важно и то, что рассмотренные принципы и технологические особенности активного формирования эмпирического знания обладают большой степенью инвариантности к предметным областям (техника, архитектура и строительство, биология, медицина, педагогика, военное дело и т.д.). Рассмотрим решатель открытых задач (РОЗ) как инструмент познания. В пределах описанной технологии человек (учащийся, слушатель, исследователь-аналитик) выполняет следующие функции: фиксирует поисковое пространство, задает начальную базу фактов, оценивает гипотезы по правилу качественной оценки. Тем самым он ставит открытую задачу. Наиболее трудоемкие в вычислительном и логическом отношениях функции синтеза текущего и искомого знаний и, главное, выдвижения гипотез берет на себя РОЗ – мощный, программно реализованный инструмент, основными блоками которого являются блок индуктивных обобщений и генератор эмпирических гипотез. Успех применения РОЗ определяется пользовательским интерфейсом, в состав которого входят редактор поискового пространства, редактор запрещенных фигур, а также средства наглядного отображения добываемых знаний. Историческая необходимость решения открытых задач возникла задолго до появления учений об открытых архитектурах в области Computer science. Первые задачи были решены при выполнении ряда исследований, связанных с поиском вариантов алгоритмической и структурной организации проблемно-ориентированных мультикомпьютерных систем [17]. Стало ясно: технология применения РОЗ во многом адекватна движению инженерной мысли, предусматривающей добывание недостающих знаний для поиска и аргументации проектных решений. Начальный опыт внедрения данной технологии в учебный процесс (в рамках дисциплины «Поисковое проектирование вычислительных систем») также оказался успешным. К настоящему времени накоплен большой опыт применения РОЗ в качестве инновационной технологии совершенствования учебного процесса как в МЭИ (ТУ) (кафедра ВМСиС, Институт безопасности бизнеса), так и за его пределами (кафедра САПР МГГУ, кафедра САУ Калужского филиала МГТУ им. Н.Э. Баумана и другие организации). Область эффективного применения РОЗ может быть значительно расширена за счет перехода к использованию сетевых коммуникационных средств актуализации исходной информации и в конечном счете актуализации добываемых знаний. Именно актуализация знаний будет способствовать усилению познавательной деятельности студентов и развитию навыков созидательного творчества. Отметим, что создание столь мощного инструментария потребует углубленной теоретической проработки и проведения обширных экспериментальных исследований, что и предполагается осуществить в обозримом будущем. Применение методов ИИ для диагностики сложных объектов на примере медицинской диагностики
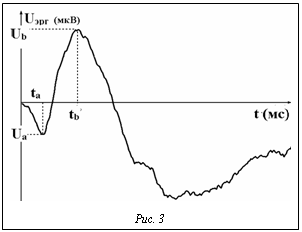
Диагностика неисправностей подобных объектов и систем часто производится с использованием набора специальных тестовых сигналов. Отклики испытуемого объекта на них пытаются сгруппировать по отличительным признакам, связываемым с видами неисправностей. Если статистические методы невозможно применить из-за ограниченности соответствующих выборок, то и использование нейронных сетей оказывается неэффективным из-за ограниченного числа характерных признаков неисправностей, выявляемых в откликах объекта. Одним из возможных способов получения дополнительных признаков, характеризующих состояние объекта, является построение адекватной логико-математичской модели объекта, на которой с помощью подстраиваемых параметров по возможности достаточно точно воспроизводится реакция реального объекта на тестовый сигнал. Для каждого случая состояния объекта числовые значения этой группы параметров могут помочь выявить вид неисправности. Во всяком случае, к объективным признакам, получаемым из конкретных временных зависимостей, добавляются параметры динамической модели, адаптированной под результаты реальных испытаний. Конечно, не всякий наблюдаемый процесс на выходе объекта поддается формальному описанию, но, если это возможно, то существенно увеличивающееся число признаков может позволить построить эффективную диагностическую систему с использованием методов ИИ, в частности, методов нечеткой логики. К подобным сложным динамическим объектам относятся не только технические объекты, но и многие биологические. Например, патология сетчатки глаза человека диагностируется как врачами-офтальмологами визуально по виду глазного дна, так и физиологами по откликам сетчатки в форме электроретинограмм (ЭРГ) на различные световые раздражители. Характерный вид ЭРГ с основными информационными признаками приведен на рисунке 3. В записях откликов сетчатки на одиночные световые импульсы в виде ЭРГ, с точки зрения экспертов-физиологов, наибольшую информацию о характере патологии несут ординаты и абсциссы первых двух экстремумов ЭРГ, отмеченные как величины Ua, ta, Ub, tb. Анализ значительного числа ЭРГ пациентов, полученных в разное время и с разных установок, показывает, что при построении экспертных систем диагностики в качестве факторов целесообразно брать не сами значения максимумов и минимумов ЭРГ, а их отношения вида При многообразии видов патологий трудно рассчитывать на возможность построения надежной экспертной системы, оперируя лишь сочетаниями четырех признаков. По этой причине на практике делаются попытки получать дополнительную информацию о состоянии сетчатки путем анализа ЭРГ на другие виды раздражителей (пачки световых импульсов, шахматные поля с чередующейся засветкой квадратов и т.д.). К сожалению, полученные в этом направлении результаты пока нельзя признать достаточно успешными. Наиболее близкой, в смысле отражения известных физиологических процессов в сетчатке, является эмпирически построенная четырехкомпонентная модель в форме структуры из четырех параллельно соединенных ветвей, каждая из которых реализует составляющие ЭРГ в виде передаточных функций (W1 для a-волны, W2 для b-волны и суммы двух передаточных функций W3+W4, реализующих c-волну) [18]:
Отметим, что обработка порядка 150 ЭРГ пациентов с различными патологиями путем подгона модельной ЭРГ к реальной дает фиксированные значения постоянных времени T1–T8 и Ta модели (1). Кроме этого, характер с-волны определяется не абсолютными значениями K3 и K4, а их разностью DK=K3–K4. Таким образом, в модели (1) имеется пять факторов, изменяющихся в зависимости от вида патологий сетчатки: коэффициент передачи a-волны Ka, коэффициент передачи b-волны Kb, транспортное запаздывание t, постоянная времени b-волны Tb и величина DK. Имеющиеся 9 признаков (предпосылок), характеризующих патологии сетчатки, делают целесообразным поиск решения на основе нечетких множеств. Для этого каждому диагнозу должны приписываться некоторые степени принадлежности. Иными словами, необходимо построить нечеткую ситуационную советующую систему, в которой пространству предпосылок ставится в соответствие пространство заключений (множество предположительных диагнозов). При решении данной задачи были отобраны группы ЭРГ, соответствующие тому или иному диагнозу, для каждой группы определены усредненные значения признаков и оценены области их отклонений. Для построения алгоритма нечеткого логического вывода формируется 9 лингвистических переменных. Показано, что количество термов в терм-множествах для них не должно превышать трех для того, чтобы вполне уверенно различать те или иные ретинальные патологии. При этом может быть выбрана самая простая, треугольная, форма функций принадлежности. Алгоритм нечеткого логического вывода строится с использованием реляционных моделей. Для этого вводится нечеткое соответствие Обобщенная нечеткая ситуация характеризуется нечетким множеством Для построения графика нечеткого соответствия
В выражении (2) символами Т и S обозначены T- и S-нормы, являющиеся нечеткими расширениями операций «И» и «ИЛИ» соответственно. В большинстве практических приложений используется максиминный логический базис, для которого нечетким расширением «И» является операция взятия минимума, а расширением «ИЛИ» – операция взятия максимума: c1 T c2 =min(c1, c2); c1 S c2= =max(c1, c2). Исследования показывают, что из-за существенного разброса числовых значений конкретных признаков пациентов относительно усредненных целесообразно строить диагностические системы под конкретные виды патологий. При этом такие системы лучше строить в виде ансамбля параллельно работающих простых подсистем с набором предпосылок не более трех. Экспериментально установлено, что при наличии 9 признаков ансамбль из 17 частных подсистем с уверенностью 0,90 диагностирует 2 вида патологий, еще 2 вида других патологий с уверенностью 0,96 диагностируют 6 частных подсистем и т.д. Следует отметить, что патологии примерно 15 % пациентов оказываются плохо различимыми, однако физиологи в большинстве таких особых случаев находят этому рациональное объяснение и не относят подобные результаты к неудовлетворительным. В настоящее время научная группа кафедры управления и информатики, руководимая профессором О.С. Колосовым, совместно с экспертами-физиологами Московского НИИ глазных болезней им. Гельмгольца создает прототип медицинской диагностической системы для сложных патологий сетчатки на основе интерпретации данных ЭРГ с использованием динамической модели сетчатки и методов нечеткой логики [18]. Комбинаторно-логические методы распознавания структурированных объектов На кафедре математического моделирования в научной группе профессора А.Б. Фролова проводятся исследования и разработки комбинаторно-логических методов распознавания структурированных объектов [19, 20]. При решении задачи распознавания оптических образов текстов, молекулярных форм, биологических объектов и в других задачах распознавания и классификации имеют дело со структурированными объектами, образуемыми как некоторые конфигурации элементов, характеризующиеся отношениями различной арности на множестве этих элементов. Известны подходы к описанию таких объектов графами или гиперграфами (мографами). Представляют интерес два новых подхода к их моделированию, которые наиболее полно объясняются на основе функциональной интерпретации. При первом из них совокупность объектов представляется в виде функции, определенной на множестве векторных описаний объектов и принимающей значения из множества возможных классов, к которым относятся все рассматриваемые объекты (функции классификации). При втором подходе сами объекты описываются конечно-значными псевдобулевыми функциями, определенными на булеане множества составных частей объекта и характеризующими отношения, которым принадлежат совокупности объектов, составляющие данный элемент булеана. Соответственно возникают два подхода к распознаванию и кластеризации. Первый, основанный на функциональной интерпретации совокупности объектов, предполагает частичную упорядоченность наборов значений, характеризующих объекты. При этом обучающая выборка описывается как частичная функция (обучающая функция), а решающая функция относит распознаваемый объект к тому классу, который определяется значением обучающей функции на наборе, ближайшем к распознаваемому по отношению частичного порядка [19]. При этом возможны как программная, так и схемная реализация алгоритма принятия решения [21]. На основе этого подхода методами теории распознавания частично упорядоченных объектов возможны построение некоторых методов распознавания оптических образов текстов, создание экспертных систем принятия решений [22], а также моделирование объектов молекулярной биологии, например, описание генетического кода [19]. Данный подход предполагает первоначальное описание решающей функции в виде ее графика или иного эквивалентного описания. В последнем случае с учетом отношения частичного порядка на множестве определения функции возможно использование граней этого множества для обобщенного задания функции, избегая перечисления всех элементов ее графика. При этом отслеживается выполнение условий непротиворечивости обобщенного задания функции и выявляются области его неполноты. Для вычисления решающей функции обобщенное описание функции классификации обрабатывается алгоритмом, выделяющим характерные точки области определения, по которым, используя значения функции классификации в них, можно восстановить значение последней в любой другой точке. Второй подход получил название принципа конечной топологии. Он заключается в моделировании реальных объектов, состоящих из элементов, совокупности которых участвуют в отношениях различной местности, определенным образом упорядоченными помеченными гиперграфами, в сравнении полученных моделей для построения тестов, определения метрики на множестве моделей и последующего применения метрических алгоритмов распознавания. Впервые принцип конечной топологии был описан применительно к задачам распознавания молекулярных форм [23]. При этом выявлено преимущество использования псевдобулевых функций по сравнению с методом моделирования на основе графов. Применение принципа конечной топологии к построению системы распознавания оптических образов текстов, описание его программной реализации и расширенное описание принципа конечной топологии в условиях использования обобщенных эталонов (эталонов в виде описаний совокупности объектов данного класса) даны в работе [20]. Рассмотрены базовые направления исследований, проводимых в научной школе ИИ МЭИ (ТУ), основателем которой является Д.А. Поспелов. Описан ряд основных, характеризующихся новизной и соответствующих мировому уровню результатов, полученных в области теории и практики создания инструментальных средств ИИ, а также в области приложений ИИ. Разработан целый спектр дополняющих друг друга инструментальных программных средств конструирования интеллектуальных (экспертных) систем, в том числе перспективных ИСППР РВ семиотического типа, зарегистрированных в Федеральной службе по интеллектуальной собственности, патентам и товарным знакам и имеющих коммерческое применение: инструментальный комплекс проектирования СППР РВ на основе таблиц решений СИМПР-Windows, инструментальное средство конструирования библиотек прецедентов и поиска решения на основе прецедентов; система временных рассуждений для точечной и точечно-интервальной моделей времени; система извлечения из корпоративной памяти знаний, релевантных проблемной ситуации; инструментальное средство обобщения понятий для обработки реальных массивов данных на основе теории приближенных множеств «Knowledge Generalizer» и др. Инструментальное средство интеграции корпоративных данных на основе системного метамоделирования и онтологии предметной области Var Pro получило международный патент. В статье представлены результаты, полученные на кафедрах института автоматики и вычислительной техники МЭИ (ТУ). Конечно, это неполный перечень всех результатов и исследований по проблематике ИИ и конструирования интеллектуальных систем, проводимых на кафедрах и в подразделениях МЭИ (ТУ). В заключение отметим, что ученые и специалисты МЭИ (ТУ), занимающиеся данной проблематикой, активно взаимодействуют с учебными, академическими и научно-исследовательскими институтами России (МГУ им. М.В. Ломоносова, МИФИ, МГТУ им Н.Э. Баумана, МИРЭА, МЭСИ, МИСИС, ТГТУ (г. Тверь), ТТИ ЮФУ (г. Таганрог), ВЦ РАН, ИПУ РАН, ИПС РАН, ИСА РАН, ВИНИТИ РАН, РосНИИ ИТиАП, НПО «АЛЬТАИР», НПО «ЦНИИКА» и другими), а также стран СНГ и дальнего зарубежья. Литература 1. Московский энергетический институт (технический университет). 1930–2005. М.: Изд-во МЭИ, 2005. 456 с. 2. Институт автоматики и вычислительной техники Московского энергетического института (технического университета) (1958–2008); под. ред. В.П. Лунина, О.С. Колосова. М.: Издат. дом МЭИ, 2008. 256 с. 3. Поспелов Д.А. Логико-лингвистические модели в системах управления. М.: Энергоиздат, 1981. 232 с. 4. Вагин В.Н. Дедукция и обобщение в системах принятия решений. М.: Наука. Глав. ред. Физматлит, 1988. 384 с. 5. Башлыков А.А., Еремеев А.П. Экспертные системы поддержки принятия решений в энергетике; под ред. А.Ф. Дьякова. М.: Изд-во МЭИ, 1994. 216 с. 6. Вагин В.Н., Головина Е.Ю., Загорянская Н.А., Фомина М.Б. Достоверный и правдоподобный вывод в интеллектуальных системах; под ред. В.Н. Вагина, Д.А. Поспелова. М.: Физматлит, 2004. 704 с. 7. Башмаков А.И., Башмаков И.А. Интеллектуальные информационные технологии: учеб. пособие. М.: Изд-во МГТУ им. Н.Э. Баумана, 2005. 312 с. 8. Еремеев А.П. К 75-летию МЭИ. Становление и развитие идей искусственного интеллекта в научной школе Московского энергетического института (технического университета) // Новости искусственного интеллекта. 2005. № 2. С. 63–66. 9. Вагин В.Н., Еремеев А.П. Исследования и разработки кафедры прикладной математики по конструированию интеллектуальных систем поддержки принятия решений на основе нетрадиционных логик // Вест. МЭИ. 2008. № 5. С. 16–26. 10.Вагин В.Н., Еремеев А.П. Некоторые базовые принципы построения интеллектуальных систем поддержки принятия решений реального времени // Изв. РАН. Теория и системы управления. 2001. № 6. С. 114–123. 11.Vagin V.N., Yeremeyev A.P. Modeling Human Reasoning in Intelligent Decision Support Systems // Proc. of the Ninth International Conference on Enterprise Information Systems. Volume AIDSS. Funchal, Madeira. Portugal. June 12–16. INSTICC, 2007, pp. 277–282. 12.Еремеев А.П., Митрофанов Д.Ю. Методы удовлетворения временных ограничений в интеллектуальных системах поддержки принятия решений реального времени // Программные продукты и системы. 2010. № 1. С. 18–23. 13.Бериша А.М., Вагин В.Н., Куликов А.В., Фомина М.В. Методы обнаружения знаний в «зашумленных» базах данных // Изв. РАН. Теория и системы управления. 2005. № 6. С. 143–158. 14.Vagin V.N., Fomina M.V., Kulikov A.V. The Problem of Object Recognition in the Presence of Noise in Original Data // 10th Scandinavian Conference on Artificial Intelligence SCAI 2008. A. Holst, P. Kruger, and P. Funk (eds.), IOS Press, Amsterdam. 2008, pp. 60–67. 15.Дзегеленок И.И. Открытые интеллектуальные системы // В кн.: Техническое творчество: теория, методология, практика: Энциклопед. слов.-справ.; под ред. А.И. Половинкина, В.В. Попова. М.: НПО «Информ-система», 1995. 408 с. 16.Дзегеленок И.И. Сетевые образовательные технологии актуализации знаний // Информационные технологии в проектировании и производстве: науч.-технич. журн. М.: Изд-во ФГУП ВИМИ. 2003. № 3. С. 10–15. 17.Дзегеленок И.И. Методология поискового проектирования вычислительных систем // Информационная математика. 2004. № 1 (4). С. 110–119. 18.Анисимов Д.Н., Вершинин Д.В., Зуева И.В., Колосов О.С., Хрипков А.В., Цапенко М.В. Использование подстраиваемой динамической модели сетчатки глаза в компонентном анализе для диагностики патологий методами искусственного интеллекта // Вест. МЭИ. 2008. № 5. С. 70–74. 19.Фролов А.Б., Яко Э. Алгоритмы распознавания частично упорядоченных объектов и их применение // Изв. РАН. Техническая кибернетика. 1990. № 5. С. 95-104. 20.Фролов А.Б. Принцип конечной топологии распознавания топологических форм // Изв. РАН. Теория и системы управления. 2010. № 1. С. 68-76. 21.Фролов А.Б., Фролов Д.А., Яко Э. Программируемые функциональные схемы для распознавания упорядоченных объектов // Изв. РАН. Теория и системы управления. 1997. № 5. С. 163-172. 22.Ополченов А.В., Фролов А.Б. Синтез и верификация экспертных систем принятия решений // Изв. РАН. Теория и системы управления. 2002. № 5. С. 101–110. 23.Frolov A.B., Jako E., Mezey P.G. Logical models of molecular shapes and their families // Kluwer Journal of Mathematical Chemistry 30, № 4, Nov. 2001, pp. 389-403. |
 Долгое время Д.А. Поспелов был организатором и руководителем общемосковского научного семинара «Проблемы искусственного интеллекта», прочитал несколько циклов лекций для преподавателей, научных работников и аспирантов по актуальным проблемам («горячим точкам») ИИ. В настоящее время Программный комитет семинара (в его состав входят представители МЭИ (ТУ), ИСА РАН, ИПУ РАН, ВИНИТИ РАН), который теперь проводится в Политехническом музее, стремится поддерживать созданную Д.А. Поспеловым творческую научную атмосферу свободного обмена идеями между представителями разных научных областей, необходимую для развития ИИ и его приложений.
Долгое время Д.А. Поспелов был организатором и руководителем общемосковского научного семинара «Проблемы искусственного интеллекта», прочитал несколько циклов лекций для преподавателей, научных работников и аспирантов по актуальным проблемам («горячим точкам») ИИ. В настоящее время Программный комитет семинара (в его состав входят представители МЭИ (ТУ), ИСА РАН, ИПУ РАН, ВИНИТИ РАН), который теперь проводится в Политехническом музее, стремится поддерживать созданную Д.А. Поспеловым творческую научную атмосферу свободного обмена идеями между представителями разных научных областей, необходимую для развития ИИ и его приложений.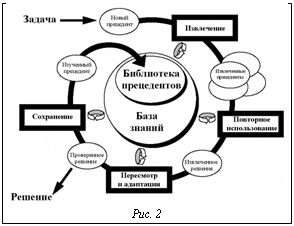 ИСППР семиотического типа может быть задана набором SS=, где M={M1, …, Mn} – множество формальных или логико-лингвистических моделей, реализующих определенные интеллектуальные функции; R(M) – множество правил выбора необходимой модели или совокупности моделей в текущей ситуации, то есть правил, реализующих отображение R(M): S®M, где S – множество возможных ситуаций (состояний), которое может быть и открытым, или S'®M, где S' – некое множество обобщенных ситуаций (состояний), например, нормальных (штатных), аномальных или аварийных, при попадании в которые происходит смена модели; F(M)={F(M1), …, F(Mn)} – множество правил модификации моделей Mi, i=1, …, n; каждое правило F(Mi) реализует отображение F(Mi): S''´ ´Mi®M'i, где S''ÍS, M'i – некоторая модификация модели Mi; F(SS) – правило модификации собственно системы SS – ее базовых конструкций M, R(M), F(M) и, возможно, самого правила F(SS), то есть F(SS) реализует ряд отображений (или комплексное отображение) F(SS): S'''´M® ®M', S'''´R(M)®R'(M), S'''´F(M)®F'(M), S'''´ ´F(SS)®F'(SS), где S'''ÍS, S'''ÇS'=Æ, S'''ÇS''=Æ, то есть правила модификации данного типа используются в ситуациях, когда имеющихся множеств моделей, правил выбора и правил модификации недостаточно для поиска решения в сложившейся проблемной ситуации [12]. Причем для модификации F(SS) могут использоваться как внутренние средства порождения моделей и правил (гипотез), так и внешние метазнания, отражающие прагматический аспект проблемной ситуации.
ИСППР семиотического типа может быть задана набором SS=, где M={M1, …, Mn} – множество формальных или логико-лингвистических моделей, реализующих определенные интеллектуальные функции; R(M) – множество правил выбора необходимой модели или совокупности моделей в текущей ситуации, то есть правил, реализующих отображение R(M): S®M, где S – множество возможных ситуаций (состояний), которое может быть и открытым, или S'®M, где S' – некое множество обобщенных ситуаций (состояний), например, нормальных (штатных), аномальных или аварийных, при попадании в которые происходит смена модели; F(M)={F(M1), …, F(Mn)} – множество правил модификации моделей Mi, i=1, …, n; каждое правило F(Mi) реализует отображение F(Mi): S''´ ´Mi®M'i, где S''ÍS, M'i – некоторая модификация модели Mi; F(SS) – правило модификации собственно системы SS – ее базовых конструкций M, R(M), F(M) и, возможно, самого правила F(SS), то есть F(SS) реализует ряд отображений (или комплексное отображение) F(SS): S'''´M® ®M', S'''´R(M)®R'(M), S'''´F(M)®F'(M), S'''´ ´F(SS)®F'(SS), где S'''ÍS, S'''ÇS'=Æ, S'''ÇS''=Æ, то есть правила модификации данного типа используются в ситуациях, когда имеющихся множеств моделей, правил выбора и правил модификации недостаточно для поиска решения в сложившейся проблемной ситуации [12]. Причем для модификации F(SS) могут использоваться как внутренние средства порождения моделей и правил (гипотез), так и внешние метазнания, отражающие прагматический аспект проблемной ситуации. , отображающих свойства предметной области (в нашем случае – вида предметной деятельности). Конкретные проявления каждого свойства отобразим именными (качественными) значениями aij,, что позволит абстрагироваться от задания в явном виде значений физических величин при построении искомой модели. Определяемым таким образом предметным переменным, а точнее, их именным значениям, можно придать причинную интерпретацию, выявляющую их взаимосвязь и степень влияния на скалярную величину g(x) обобщенного показателя качества, где x=(x1, …, хn). В таком понимании искомую модель можно также трактовать как некоторое каузальное, или причинно-следственное, знание.
, отображающих свойства предметной области (в нашем случае – вида предметной деятельности). Конкретные проявления каждого свойства отобразим именными (качественными) значениями aij,, что позволит абстрагироваться от задания в явном виде значений физических величин при построении искомой модели. Определяемым таким образом предметным переменным, а точнее, их именным значениям, можно придать причинную интерпретацию, выявляющую их взаимосвязь и степень влияния на скалярную величину g(x) обобщенного показателя качества, где x=(x1, …, хn). В таком понимании искомую модель можно также трактовать как некоторое каузальное, или причинно-следственное, знание. , сопоставляемых или оговоренным значениям, или интервалам значений параметра pi, или любым его возможным проявлениям (например, вид, тип аппаратных или программных средств).
, сопоставляемых или оговоренным значениям, или интервалам значений параметра pi, или любым его возможным проявлениям (например, вид, тип аппаратных или программных средств).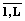 , T=
, T=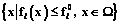 .
.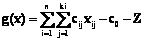 .
. Диагностика неисправностей в сложных динамических объектах и системах является хорошо известной проблемой и, как правило, не имеет четких алгоритмов решения. Во многих случаях опыт и интуиция обслуживающего персонала (ЛПР) играют ключевую роль в своевременном выявлении и устранении неисправностей. На основании такого опыта делаются попытки создания алгоритмов поиска неисправностей сложного объекта (системы) для менее квалифицированных работников. Однако наличие неформализованных признаков часто характеризуют целые наборы возможных неисправностей. Что касается формализованных признаков, характеризуемых средними значениями и областями отклонений, то во многих случаях эти области пересекаются для разного рода неисправностей.
Диагностика неисправностей в сложных динамических объектах и системах является хорошо известной проблемой и, как правило, не имеет четких алгоритмов решения. Во многих случаях опыт и интуиция обслуживающего персонала (ЛПР) играют ключевую роль в своевременном выявлении и устранении неисправностей. На основании такого опыта делаются попытки создания алгоритмов поиска неисправностей сложного объекта (системы) для менее квалифицированных работников. Однако наличие неформализованных признаков часто характеризуют целые наборы возможных неисправностей. Что касается формализованных признаков, характеризуемых средними значениями и областями отклонений, то во многих случаях эти области пересекаются для разного рода неисправностей.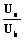 или
или 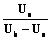 .
. (1)
(1)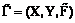 , где X – область отправления (множество типовых ситуаций); Y– область прибытия (множество возможных диагнозов);
, где X – область отправления (множество типовых ситуаций); Y– область прибытия (множество возможных диагнозов); 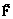 – график нечеткого соответствия.
– график нечеткого соответствия.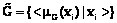 ,
, 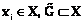 , элементы которого представляют все возможные сочетания термов.
, элементы которого представляют все возможные сочетания термов.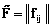 . Нечеткое множество возможных патологий
. Нечеткое множество возможных патологий  определяется как композиция входной нечеткой ситуации
определяется как композиция входной нечеткой ситуации 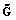 и нечеткого графика
и нечеткого графика 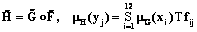 . (2)
. (2)| Permanent link: http://swsys.ru/index.php?id=2550&lang=en&page=article |
Print version Full issue in PDF (5.84Mb) Download the cover in PDF (1.43Мб) |
| The article was published in issue no. № 3, 2010 |
Perhaps, you might be interested in the following articles of similar topics:
- Прецедентный подход для оценки влияния молний на системы уличного освещения с использованием онтологий
- Задачи построения интеллектуальной информационной системы управления безопасностью дорожного движения
- Абдуктивный вывод versus дедукция
- Методы удовлетворения временных ограничений в интеллектуальных системах поддержки принятия решений реального времени
- Интеллектуальная поддержка принятия решений в экспертных системах при диагностике заболеваний полости рта
Back to the list of articles