Journal influence
Bookmark
Next issue
Approach to implementing automated search ontological information source
The article was published in issue no. № 2, 2011Abstract:In this article describes an approach to improve search relevance of ontologies in information sources on the example of the structure of the automated search of ontological information in the source. A comparative analysis of the percentage of accuracy of a search using a standard approach and is described.
Аннотация:Описывается подход для повышения релевантности поиска онтологий в источниках информации на примере структуры системы автоматизированного поиска онтологической информации в источнике. Дается сравнительный анализ точности поиска с использованием стандартного и описываемого подходов.
| Authors: Chokhonelidze A.N. (444595@pochtf.ru) - Tver State Technical University, Tver, Russia, Ph.D, (mail@artellab.ru) - | |
| Keywords: algorithm to search for ontologies, relevant search, the ontological search, the ontological search, ontology |
|
| Page views: 13635 |
Print version Full issue in PDF (5.35Mb) Download the cover in PDF (1.27Мб) |
Информационные системы, применяемые на современных предприятиях, в большинстве своем разрозненные, и это создает серьезные проблемы. Причин, вследствие которых созданная информационная система предприятия по сути не является единой, множество, в частности: · нехватка средств для создания законченной системы; · автоматизация собственными силами, отсутствие необходимого опыта; · низкая заинтересованность руководства или иных ответственных сотрудников; · длительная, многолетняя автоматизация бизнеса; · преследование иных целей, например, оптимизация налогообложения. Чтобы такая система работала, то есть позволяла получать информацию о состоянии дел на предприятии, необходимо прилагать достаточно много усилий: осуществлять двойной или даже тройной ввод информации в разных подсистемах, сверять информацию в разных БД и исправлять несоответствия, накапливать и обрабатывать много избыточной информации. На обслуживание такой информационной системы требуются дополнительные расходы. С ростом предприятия проблема разрозненности данных только усугубляется. Появление новых отделов, магазинов, офисов ведет к возникновению новых источников и потребителей информации из информационной системы. А поскольку изначально созданная система не была рассчитана на расширение масштабов бизнеса, происходит лавинообразный рост несогласованности данных между существующими отдельными информационными системами. Для решения задачи консолидации ресурсов, относящихся к одной области знаний, в единое информационное пространство необходимо обеспечить качественный поиск онтологической информации. Технология ее сбора в источнике включает два основных этапа: определение типа источника, его принадлежности к предметной области и внесение информации в БД. В статье рассматривается подход к реализации сбора онтологической информации и дается оценка показателей качества найденной информации с использованием данного подхода и без него. Общая схема сбора онтологической информации представлена на рисунке 1.
На этапе обработки текста документа необходимо определить его категорию (классифицировать или кластеризовать текст документа). Для этого используется подсистема индексирования текстов документов, являющаяся основным ядром всей системы и одновременно ее особенностью. Большинство существующих систем поиска онтологий основывается на поиске соответствия начальной формы слова слову в словаре. Для русского языка данный подход является неверным, так как одно и то же слово в разных предложениях может не только не совпадать по смыслу, но и совершенно не соответствовать определенной области знаний. Следует отметить, что поиск релевантной информации является основной проблемой всех поисковых систем. Разрабатываемая подсистема индексирования текстов документов анализирует не слова, а предложения и извлекает необходимые соответствия из онтологического словаря. Словарь в данном случае также содержит примеры онтологий, а при сравнении выбирается наиболее схожая из них. Кроме того, словарь может быть обучен, однако при применении системы обучения несколькими пользователями через Интернет обучение от разных учителей может оказаться противоречивым. Для решения проблемы возможна разработка прослойки между учителем и словарем – предварительное накопление информации для обучения от разных учителей и online обучение словаря на основании статистического отбора из предварительной базы обучения. Подсистему индексирования можно модернизировать, добавив анализ связи между предложениями. Данная задача может быть востребована при анализе схожести текстов документов и в рамках данной статьи не рассматривается.
На вход алгоритма подается морфологический вариант клаузы. В программе задан некоторый порядок применения правил. Он соответствует порядку построения групп – от меньших к большим. Например, сначала надо построить группы МОДИФ-ПРИЛ, а потом ПРИЛ-СУЩ, чтобы построить структуру на отрезке «очень красивый человек»: ПРИЛ-СУЩ (МОДИФ-ПРИЛ (очень красивый), человек) [1, 2]. Все правила поочередно применяются к каждому слову входного отрезка слева направо. Каждое правило для вновь построенной группы указывает ее главную группу, список граммем (обычно берется из списка граммем главного слова), тип. Компоненты, составляющие языковую модель, – это лингвистические процессоры, которые друг за другом обрабатывают входной текст. Вход одного процессора является выходом другого. В модели выделяются следующие компоненты: · графематический анализ – выделение слов, цифровых комплексов, формул и др.; · морфологический анализ – построение морфологической интерпретации слов входного текста; · синтаксический анализ – построение дерева зависимостей всего предложения; · семантический анализ – построение семантического графа текста. Для каждого уровня имеется свой язык представления, который, как и полагается, состоит из констант и правил их комбинирования. На графематическом уровне константами были графематические дескрипторы (ЛЕ – лексема, ЦК – цифровой комплекс и др.). На морфологическом уровне – граммемы (рд – родительный падеж, мн – множественное число). На синтаксическом – названия отношений и групп (ПОДЛ – отношение между подлежащим и сказуемым, ПГ – предложная группа). На семантическом – семантические категории и отношения. С каждого уровня представления можно сделать переход (трансфер) к такому же представлению на другом естественном языке. Основой для построения уровней служат результаты работы предыдущих этапов, но, что важно, последующие анализаторы также могли улучшить представление предыдущих. Например, для какого-то предложения синтаксический анализатор не смог построить полное дерево зависимостей, тогда, возможно, семантический анализатор сможет спроектировать построенный им семантический граф на синтаксис. Графики, отображающие точность поиска онтологий с использованием системы разбора предложений и словаря онтологий и без системы разбора предложений, приведены на рисунке 2. На графиках по оси X указано количество полученных предложений, по оси Y – релевантность поиска онтологий. Из графиков видно, что с помощью поиска онтологий с использованием разбора предложений можно приблизиться к большей релевантности, однако из-за тесной связи между синтаксисом и семантикой абсолютного совпадения с ручным поиском достичь практически невозможно. Сложность реализации связана с наличием тесной связи между синтаксисом и семантикой, присутствием в текстах русского языка большого количества синтаксически омонимичных конструкций, не допускающих однозначной интерпретации без привлечения знаний о семантической сочетаемости слов. Такова, например, проблема управления глагола предложно-падежными конструкциями. В синтаксически эквивалентных фразах «человек стрелял из ружья» и «человек стрелял из окна» объект «ружье» представляет аргумент предиката «стрелять» в роли косвенного дополнения, а объект «окно» – обстоятельство места, которое является дополнительной характеристикой всей ситуации в целом. Перед системами анализа текста стоят такие задачи: формирование информационного портрета текста в терминах ключевых понятий, выявление смысловых связей между понятиями, автоматическое реферирование. Прикладные функции интеллектуальных систем, которые могут быть реализованы на основе этих результатов, описаны в работе [3]. Важнейшей сопутствующей проблемой, решаемой исключительно средствами синтаксического анализа, является разрешение омонимии в тех случаях, когда грамматические формы различных слов совпадают (например, форма «стали» для существительного «сталь» и глагола «стать»). Статистические методы анализа текста, на которых до настоящего времени были сконцентрированы усилия разработчиков интеллектуальных систем, достигли своего естественного предела. Дальнейшее усложнение математики без серьезного привлечения лингвистики не позволит заметно повысить качество подобных систем. К сожалению, внедрение математических методов в обработку текста проходит на фоне отсталости собственно лингвистической составляющей алгоритмов, что не позволяет достичь высокого качества работы прикладных систем. Описанный подход позволяет извлекать знания из источников с большей релевантностью, и это в некоторой степени решает проблему математической обработки текстов. Литература 1. Ермаков А.Е. Тематический анализ текста с выявлением сверхфразовой структуры // Информационные технологии. 2000. № 11. 2. Плешко В.В., Ермаков А.Е., Липинский Г.В. TopSOM: визуализация информационных массивов с применением самоорганизующихся тематических карт // Информационные технологии. 2001. № 8. 3. Ермаков А.Е., Плешко В.В. Тематическая навигация в полнотекстовых базах данных // Мир ПК. 2001. № 8. 4. URL: http://aot.ru/docs/fragman.html (дата обращения: 10.12.2010). |
 Подсистема извлечения текстов получает документ, определяет его тип (например, .html, .doc, .pdf, .jpg и др.), кодировку и записывает текстовую информацию в БД. На данном этапе происходят очистка документов и сохранение только той информации, которая содержит знания.
Подсистема извлечения текстов получает документ, определяет его тип (например, .html, .doc, .pdf, .jpg и др.), кодировку и записывает текстовую информацию в БД. На данном этапе происходят очистка документов и сохранение только той информации, которая содержит знания.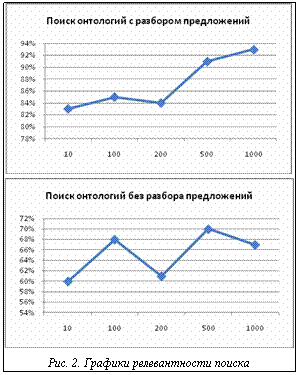 Для поверхностного анализа синтаксиса предложений используется система от разработчиков aot.ru.
Для поверхностного анализа синтаксиса предложений используется система от разработчиков aot.ru.| Permanent link: http://swsys.ru/index.php?id=2776&lang=en&page=article |
Print version Full issue in PDF (5.35Mb) Download the cover in PDF (1.27Мб) |
| The article was published in issue no. № 2, 2011 |
Perhaps, you might be interested in the following articles of similar topics:
- Онтологии для реализации обратной трассировки при разработке и сопровождении программ
- Мультиагентная система распределения производственных ресурсов в тяжелом машиностроении
- Подсистема воспроизведения иммерсивных виртуальных тренажеров с биологической обратной связью
- Расширение базы знаний с учетом доверия к новому знанию
- Автоматизация оценки знаний студентов в системе электронного обучения ECOLE
Back to the list of articles