Journal influence
Bookmark
Next issue
Software system for disease diagnosis by chromatogram of blood serum sample
Abstract:High-performance liquid chromatography (HPLC) with multichannel UV-detection has an important place in analytical chemistry. This method allows qualitative and quantitative analysing of substances in unknown samples. Current work isaimed to develop a software system that allows processing and classifying chromatograms. The mining information from input data process includes applying smoothing filters, finding chromatographic peaks and calculating its characteristics called “chromatographic fingerprint”: retention volume, peak area and spectrum. Further processing of receivedinformation is to identify similar peaks in different chromatograms by metric classification of its spectra, followed by transfer chromatogramsto a vector representation, decrease its dimensions and use fuzzy clustering algorithms. After finding main attributes of all clusters the work to optimize analysis method is provided. Optimization is based on modelling the chromatographic process of samples under different conditions. The system reliability depends on the parameters of the algorithms and the quality and quantity of training sets given by an expert. The developed software solution allows diagnosing of diseases including cancer, based on serum samples analysis (sample composition isunknown). It is also possible to use it in other areas of analytical chemistry, such as drugs standardization, foods and dietary supplements.
Аннотация:Высокоэффективная жидкостная хроматография с многоканальным ультрафиолетовым детектированием занима-ет важнейшее место в аналитической химии. Этот методпозволяет выполнять как качественный, так и количествен-ный анализ веществ в неизвестных образцах. Целью работы является создание программной системы, позволяющей проводить обработку и классификацию хроматограмм. Процесс обработки включает в себя сглаживание и нормали-зацию сигнала ультрафиолетового детектора, выделение отдельных компонентов, сравнение и кластеризацию дан-ных на основе информации об объеме удерживания вещества, площади его хроматографического пика и на основе его спектральных характеристик. В совокупности эти параметры составляют основу формата «chromatographic fingerprint». Дальнейшая обработка полученной информации заключается в обнаружении одинаковых пиков в раз-ных хроматограммах путем метрической классификации их спектров с последующим переводом хроматограмм в векторное представление, понижением их размерности и применением к ним алгоритмов нечеткой кластеризации. После выделения основных признаков каждого кластера проводится работа по оптимизации методики анализа путем математического моделирования процесса хроматографирования образцов при различных условиях. Досто-верность ответов системы зависит от задаваемых экспертом параметров алгоритмов выделения информации, качест-ва и объема обучающих выборок. Разработанное программное решение позволяет проводить диагностику различных заболеваний, включая онкологические, основываясь на результатах анализа образцов сыворотки крови, состав кото-рых заранее неизвестен, а также может найти применение втаких областях химического анализа, как стандартизация состава лекарственных средств, биологически активных добавок и продуктов питания.
| Authors: Baram E.G. (egbaram@gmail.com) - A.P. Ershov Instituteof Informatics Systems (IIS), Siberian Branch of the Russian Federationn Academy of Sciences, Novosibirsk, Russia | |
| Keywords: expert system, noise filtering, , multiwave chromatography, clusterization, |
|
| Page views: 12018 |
Print version Full issue in PDF (12.50Mb) Download the cover in PDF (0.36Мб) |
Достижения в области информационных технологий за последние 20 лет обусловили прогресс во многих областях науки, в частности, в аналитической химии и особенно в тех ее разделах, которые связаны с обработкой большого объема экспериментальных данных. Одним из таких разделов является жидкостная хроматография – метод разделения веществ в растворе, который впервые ввел в практику в 1903 году М.С. Цвет [1]. Суть метода заключается в следующем: в верхнюю часть хроматографической колонки, представляющей собой трубку, наполненную мелкодисперсным адсорбентом, помещают небольшую порцию раствора анализируемого образца и промывают колонку подходящим растворителем. Важно, чтобы молекулы компонентов образца в данном растворителе быстро адсорбировались и десорбировались с поверхности сорбента. В этом случае молекулы каждого типа будут передвигаться по колонке в виде узких концентрационных зон со скоростью, обратно пропорциональной силе адсорбции. Очевидно, что если сила взаимодействия адсорбата с адсорбентом для молекул разных веществ будет различной, то и скорости движения зон этих веществ будут различаться, то есть вещества, проходя через колонку, разделятся.
Зависимость величины концентрации вещества вдоль зоны в идеальном случае описывается уравнением Гаусса: Наблюдаемая кривая называется хроматографическим пиком. Если измерять концентрацию веществ в растворе на выходе колонки, получим кривую, которая называется хроматограммой. Таким образом, хроматограмма является функцией зависимости концентрации вещества в растворе от объема пропущенного через колонку растворителя или от времени. Каждому веществу на хроматограмме соответствует свой пик. Абсцисса вершины пика называется объемом удерживания вещества (VR), величина которого определяется химическим строением этого вещества, составом подвижной фазы, свойствами адсорбента (неподвижной фазы) и температурой. Мерой количества вещества в пробе является площадь хроматографического пика. В настоящее время среди многих методов химического анализа заметное место занимает высокоэффективная жидкостная хроматография (ВЭЖХ) с многоканальным детектированием и, в частности, с многоволновой фотометрией в ультрафиолетовой (УФ) области спектра. Важным направлением ВЭЖХ-УФ в последнее время можно считать «стандартизацию» обзорного анализа сыворотки крови человека [2]. После обработки хроматографической и спектральной информации становится возможным отслеживание значимых изменений в составе крови, а значит, проведение диагностики ряда заболеваний. В данной работе предлагается вариант компьютерной системы, способной обрабатывать результаты такого анализа. В этом процессе вы- деляют два основных этапа: обработка сигнала детектора (сглаживание, приведение к единой временной шкале, удаление выбросов) и кластеризация с последующим анализом полученных компонентов для сравнения их с эталоном или идентификации по базе данных ВЭЖХ-УФ. Идентификация компонентов может производиться по времени удерживания и спектральным отношениям, что дает возможность различать более 1011 веществ. Общая схема работы системы представлена на рисунке 1.
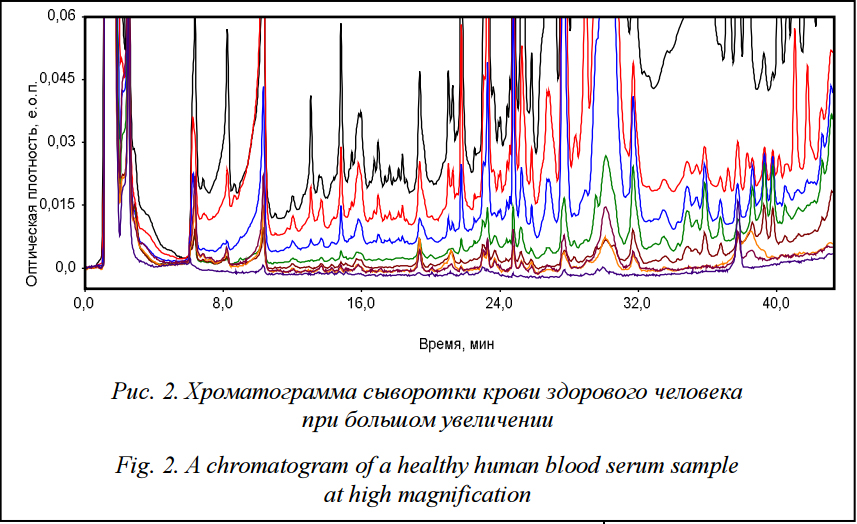
Методы На рисунке 2 приведен пример данных, получаемых с хроматографа в 8-волновом режиме. Массив данных содержит в общей сложности около 40 тысяч точек.
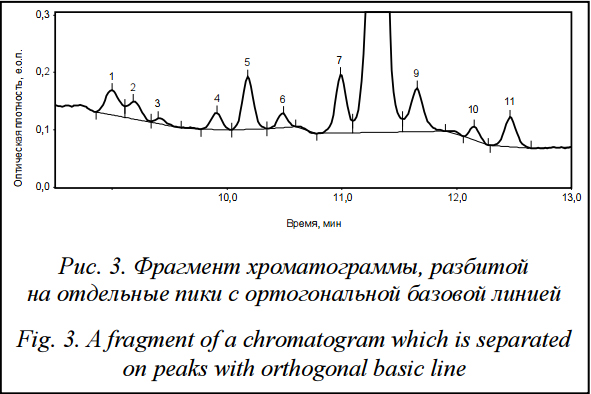
Обычно сигнал детектора имеет относительно высокий уровень шума, что, разумеется, затрудняет обнаружение пиков. Кроме того, главной проблемой при такого рода анализах является то, что каждый пик может иметь существенный дрейф и накладываться на соседние пики. Фильтрация может понизить уровень шумов спектра за счет их сглаживания. Влияние того или иного фильтра на результат зависит от его вида. Например, семиразрядный фильтр Савицкого–Голея дает видимое улучшение [3, 4]. Его влияние возрастает при расширении полосы фильтрации. К сожалению, подобрать систему фильтров, подходящую для любых типов входных данных, чрезвычайно сложно. Нами было установлено, что при обработке хроматограмм сыворотки крови наилучшие результаты достигаются при использовании SG-фильтра с окном от 7 до 15 точек [4–6]. Выделение пиков Разбиение отфильтрованной хроматограммы на отдельные пики является наиболее ресурсоемкой частью анализа. В данном случае использовался хорошо зарекомендовавший себя алгоритм детектирования пиков, основанный на изучении поведения первой производной хроматографической кривой. Чтобы определить, является ли наклон в данной точке значимым, величина производной делится на величину шума так называемой базовой линии [5, 6]. Наклон считается значимым, если вычисленное отношение превышает величину, называемую порогом срабатывания. Общая схема алгоритма выглядит следующим образом. 1. Вход: массив точек. 2. Вычислить значение производной в каждой точке. 3. На основании значения производной и уровня шумов присвоить каждой точке тип – «возрастание», «убывание» или «плато». 4. Объединить соседние точки одного типа в группы. 4.1. Найти группу точек типа «возрастание». 4.2. Найти следующую за ней группу точек типа «убывание». 4.3. Объединить группы в пик и перейти к п. 4.1. 5. Определить положение вершины каждого получившегося пика. 6. Выход: массив координат пиков. Соседние пики разделятся вертикальными прямыми. Пример результата работы алгоритма приведен на рисунке 3.
Сравнение компонентов Очевидно, что спектрограмма является вектором в евклидовом пространстве соответствующей размерности. Мерой близости между двумя спектрами служит угол, образуемый этими векторами. На первом шаге алгоритма обе хроматограммы разбиваются на пики, после чего строится таблица соответствия (см. табл. 1). Пики первой хроматограммы обозначаются буквами, второй – цифрами. В ячейки таблицы вписаны расстояния (в данном случае это временные дистанции) между вершинами соответствующих пиков и углы между их спектрами. Затем из таблицы удаляются ячейки, в которых отклонения превышают заданные экспертом величины, после чего «жадным» алгоритмом поиска паросочетаний минимального веса находятся наилучшие кандидаты (выделены полужирным шрифтом). Таблица 1 Соответствие пиков на двух хроматограммах Table 1 Peaks conformity for two chromatograms
Таким образом строится словарь соответствий между пиками двух хроматограмм. При необходимости построить соответствие между несколькими хроматограммами (например, для выявления одинаковых пиков на наборе эталонных образцов) этот процесс выполняется многократно. Выделение значимых признаков После нахождения соответствий между пиками в одном наборе хроматограмм выбираются пики, которые можно считать значимыми признаками того или иного класса веществ. Будем считать значимыми пики, для которых разность частот их появления в различных источниках превышает 50 %. При этом размерность рассматриваемых векторов уменьшается с 300–400 до 20–30. Эти векторы формируют так называемые «отпечатки пальцев», описывающие признаки, характерные для определенного класса веществ. Таблица 2 Результат построения «хроматографического отпечатка пальца» Table 2 The result of the «chromatographic fingerprint» construction
В первом столбце таблицы 2 указано среднее время удерживания пика, во втором и третьем – доля образцов сыворотки крови здоровых и больных людей соответственно, содержащих этот пик. Кластеризация и сравнение хроматограмм В результате описанных выше действий мы получаем хроматограмму в виде уже не нескольких массивов пар «время–оптическая плотность» или набора времени удерживаний, площадей и спектров, а вектора, элементами которого являются значения площадей соответствующих пиков. Набрав достаточное количество хроматограмм сыворотки крови здоровых и больных людей, мы можем использовать их в качестве обучающих выборок для кластеризации. Для этого в разработанной системе применяются алгоритм нечеткой кластеризации C-means и метод ближайших соседей, в котором в качестве квазиметрики используется функция конкурентного сходства FRiS [7]. После создания обучающих выборок «сыворотка крови здоровых–сыворотка крови больных» появляется возможность определить, к какому кластеру принадлежит данная хроматограмма. Оптимизация методики анализа Последний этап создания системы заключается в создании оптимизированных методик проведения анализа с целью сокращения времени хроматографии и повышения точности определения наличия пиков-признаков. Для этого была построена математическая модель, в основе которой лежит следующее уравнение:
где k′0 и n – параметры удерживания компонента смеси; V0 – свободный объем хроматографической колонки; C(v) – функция, описывающая форму градиента (в % растворителя Б); VR – искомый объем удерживания вещества [8, 9]. Уравнение (1) может быть использовано и для решения обратной задачи, то есть для нахождения констант k′0 и n, описывающих поведение вещества при хроматографировании, по результатам двух экспериментов с заранее известными функциями C(v):
Поиск решения системы уравнений (2) выполняется с применением метода Ньютона с критерием остановки σ ≤ 5 мкл. После получения констант k′0 и n можно предсказать результаты эксперимента в любых заданных условиях, используя для этого уравнение (1). Процедура оптимизации заключается в подборе такого вида функции C(v), что коэффициенты разделения всех веществ-признаков будут не меньше заданной величины, а объем удерживания последнего вышедшего вещества будет минимальным [10]. Таким образом, была создана программная система, включающая в себя блок управления хроматографом и блок обработки получаемых хроматограмм. Процесс выделения информации из входных данных состоит из фильтрации шумов сигнала детектора, выделения хроматографических пиков и вычисления их характеристик. Дальнейшая обработка полученной информации заключается в сравнении пиков в разных хрома- тограммах путем классификации их спектров с последующим переводом хроматограмм в векторное представление и применением к ним алгоритмов нечеткой кластеризации. Достоверность ответов системы зависит от задаваемых экспертом параметров алгоритмов выделения информации и качества обучающих выборок. Литература 1. Цвет М.С. О новой категории адсорбционных явлений и о применении их к биохимическому анализу // Тр. Варшавского об-ва естествоиспытателей. 1903. № XIV. С. 1–20. 2. Kozhanova L.A. Determination of anti-tuberculosis drugs in human serum by HPLC. Proc. 8th Analytical Russian-German-Ukrainian Symposium. Germany, Hamburg, 2003, pp. 79–83. 3. Heyden Y.V. Extracting Information from Chromatographic Herbal Fingerprints. LCGC Europe. 2008, no. 9, pp. 438–443. 4. Savitzky A., Golay M.J.E. Smoothing and differentiation of data by simplified least squares procedures. Analytical Chemistry. 1964, no. 36 (8), pp. 1627–1639. 5. Dyson N. Chromatographic Integration Methods. Letchworth, UK: 2nd ed. Royal Society of Chemistry, 1998, 202 p. 6. Хубер Л. Применение диодно-матричного детектирования в ВЭЖХ. М.: Мир, 1993. 92 с. 7. Загоруйко Н.Г., Борисова И.А. Функции конкурентного сходства в задаче таксономии // Знания-Онтологии-Теории (ЗОНТ-2007): матер. Всеросс. конф. с междунар. участием (14–16 сентября 2007 г., Новосибирск). Н.: Изд-во ИМ СО РАН. Т. 2. С. 113–116. 8. Snyder L., Dolan J. High-Performance gradient elution. Wiley-Interscience, 2007, pp. 45–51. 9. Jandera P., Churacek J. Gradient Elution in Column Liquid Chromatography. Journ. of Chromatography, 1985, vol. 31. 10. Cela R., Martinez J.A. Multi-objective optimisation using evolutionary algorithms: its application to HPLC separations. Chemometrics and Intelligent Laboratory Systems, 2003, no. 69, pp. 137–156. | ||||||||||||||||||||||||||||||
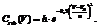

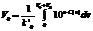 , (1)
, (1) (2)
(2)| Permanent link: http://swsys.ru/index.php?id=3968&lang=en&page=article |
Print version Full issue in PDF (12.50Mb) Download the cover in PDF (0.36Мб) |
| The article was published in issue no. № 1, 2015 [ pp. 117-120 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Дополнение к алгоритму кластеризации беспроводной сенсорной сети
- Трехтактная кластеризация динамичных интернет-ресурсов с применением DOM-моделей
- О некоторых проблемах предметной области поддержки принятия решений
- Экспертная система для определения стиля математического мышления
- Нейронечеткая система обнаружения продукционных зависимостей в базах данных
Back to the list of articles