Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: Shabanov, B.M. (jscc@jscc.ru) - Joint Supercomputer Center of RAS (Corresponding Member of the RAS, Director), Moscow, Russia, Ph.D, P.N. Telegin (pnt@jscc.ru) - Joint Supercomputer Center of RAS (Leading Researcher), Moscow, Russia, Ph.D, (aladyshev@jscc.ru) - , Ph.D | |
| Keywords: , , modeling, programming |
|
| Page views: 27186 |
Print version Full issue in PDF (1.83Mb) |
В статье рассматриваются модели программирования и модели выполнения программ на кластерах с многоядерными процессорами. Зависимость программных моделей и архитектурных решений для параллельной обработки данных является взаимозависимой. С одной стороны, при разработке новых вычислительных систем учитываются уже имеющийся опыт программирования. С другой стороны, возможности новых вычислительных систем оказывают влияние на развитие методов программирования. Рассматривались модели с явно выраженным способом организации параллельных вычислений: модель с общей памятью и модель на основе передач сообщений [1] многоядерных процессоров. Рассматривались особенности подготовки параллельных программ для многоядерных процессоров. Проводились исследования с использованием процессоров Intel Xeon 5160 (Woodcrest) и Intel Xeon 5365 (Clovertown). Процессор Intel Xeon 5160 (Woodcrest) представляет собой двухъядерный процессор с тактовой частотой 3 ГГц. Два процессора используют общий кэш второго уровня объемом 2 МБ и общую шину с частотой 1333 МГц. Процессор Intel Xeon 5365 (Clovertown) является четырехъядерным процессором с тактовой частотой 3 ГГц и представляет собой два двухъядерных процессора Woodcrest, выполненных в одном корпусе. Соответственно, общий кэш объемом 3 МБ используется парой процессоров. В настоящее время на материнскую плату могут устанавливаться два таких процессора. Таким образом, в одном узле с общей памятью могут одновременно работать восемь ядер. На первый взгляд, такая архитектура не отличается от классических SMP-систем. Однако здесь имеются важные особенности: совместное использование кэш-памяти двумя процессорами и подключение по шине [2], которые делают крайне важным размещение процессов по процессорам. Для использования в научных вычислениях узлы, содержащие многоядерные процессоры, объединяются в кластеры [3]. Рассмотрим подробнее специфические отличия при использовании многоядерных процессоров в высокопроизводительных вычислениях. Они включают в себя конкуренцию за память и сетевые соединения, локальность программ по данным и используемые модели программирования. Использование общей кэш-памяти. В отличие от классических SMP-систем несколько ядер имеют общий кэш. Это увеличивает производительность при миграции задач по процессорам за счет того, что данные могут оставаться в кэше. С другой стороны, при определенных размерах задач использование всей кэш-памяти одним процессором может иметь настолько важное значение, что использование только одного ядра может дать более высокую производительность. Конфликты по памяти. Многоядерные системы являются системами с распределенной памятью. Несмотря на продолжающиеся разработки в области подсистем памяти, часто возникает ситуация, когда один сегмент памяти должен обслуживать два или более ядер. Это, разумеется, снижает производительность. Конфликты по сетевым соединениям. Приложения, требующие высокопроизводительной техники, обычно выполняются на кластерах и используют библиотеки MPI для обмена даны- ми [3]. Большое количество ядер (до 16 в узле в распространенных кластерных системах) приводит к конкуренции за сетевые ресурсы. Миграция процессов. В узлах, использующих многоядерные процессоры, операционная система принимает решения о расположении процессов по процессорам. Операционная система пытается поддерживать сбалансированность загрузки процессоров путем миграции процессов по процессорам. Когда процесс помещается на ядро, использующее другой кэш, требуется загрузка кэш-памяти данными заново, при этом снижается производительность. Было протестировано использование опции привязки процесса к процессору на стандартных бенчмарках. Привязка к процессору (Processor Affinity) возможна, в частности, при использовании HPMPI (опция «-cpu_bind»). Результаты показывают, что при использовании привязки процесса к процессору уменьшается дисперсия при измерении времени выполнения программы, однако уменьшения среднего времени выполнения программы не обнаружено. Вполне возможно, что данный результат обусловлен неудачной стандартной привязкой процессов. Модели программирования. Наиболее широко в высокопроизводительных вычислениях применяется среда MPI, использующая модель с распределенной памятью. В одном узле ядра работают над общей памятью, и MPI производит передачу данных через общую память. При этом также используются модели программирования с общей памятью, такие как нитевое программирование. Наиболее простой способ использовать нити – это набор директив OpenMP [4]. Особый интерес представляет комбинированная модель с нитями внутри узла кластера и с использованием MPI между узлами. Для выбора параметров параллельной программы (в том числе автоматического) с учетом многоядерной архитектуры рассматривались конфликты по памяти, например, широко используемый случай операции x=x+ai*bi. При использовании многоядерной архитектуры и при больших объемах данных необходимые элементы ai и bi не успевают считываться из памяти, и возникает конкуренция за память. В этом случае время считывания из памяти принимаем равным следующей величине:
где N – длина вектора для каждого процесса (0£i£N); Vb – скорость считывания данных из памяти. Для конфликтов по памяти можно использовать коэффициент CR, который определяется для конкретной системы с учетом объема используемых данных. Такой способ позволяет проводить оценки при небольшом использовании вычислительных ресурсов. Рассмотрим гнездо циклов. do i1=1, n1 … do ik=1, nk x(i1)=f(i1,…,ik, данные) enddo … enddo Рассмотрим распределение итераций циклов по процессорам. Если итерации не связаны друг с другом, их можно распределять по кластерам и узлам конкретного кластера произвольным образом. Время выполнения гнезда циклов на разнородной системе при дуплексной передаче данных определяется по формуле: Tц=
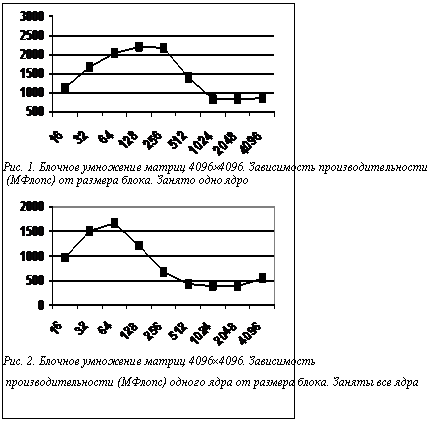
где Для определения оптимальной загрузки требуется минимизировать функцию (2). Для этого адаптируются инструментальные средства, построенные на вышеуказанных принципах. На рисунках 1 и 2 приводятся результаты тестирования умножения матриц в зависимости от размерности на одном и четырех ядрах на системе HP BL460c с использованием процессоров Intel Xeon 5160. Можно видеть, что после заполнения кэш-памяти происходит снижение производительности. Кроме того, видно, что производительность одного ядра при одновременной работе четырех также снижается. Заметим, что при размере блока 256´256 суммарная производительность при использовании четырех ядер практически совпадает с производительностью одного ядра. Это может быть объяснено использованием преимущественно кэш-памяти при использовании одного ядра и преимущественно оперативной памяти при использовании четырех ядер. В нашем случае коэффициент СR в стационарном режиме достигает значения 1,6. Заметим, что пиковые значения производительности превышают 3, что объясняется полным заполнением общей кэш-памяти двумя ядрами.
Опыт использования многоядерных процессоров показывает, что при большом числе виртуальных систем целесообразным становится уменьшение сложности задачи, для этого возможно распределение циклов гнезда по уровням неоднородной системы. В этом случае строится иерархический набор виртуальных систем, уровням которого назначаются циклы из гнезда. Список литературы 1. Телегин П.Н., Шабанов Б.М. Связь моделей программирования и архитектуры параллельных вычислительных систем. // Программные продукты и системы. – 2007. - №2. 2. Douglas Eadline. Optimized HPC Performance: MPI Strategies for Next Generation Quad-Core Intel®Xeon® Processors. (http://basement-supercomputing.com/download/reports/harpertown-WP1-rev3.pdf) 3. Савин Г.И., Телегин П.Н., Шабанов Б.М. Кластеры Беовульф. // Изв. вузов. Электроника. – 2004. - № 1. - С. 7-12. 4. BLAS (Basic Linear Algebra Subprograms). http://www.netlib.org/blas/ |
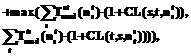 (2)
(2) Отдельный вопрос – использование возможностей оптимизации компиляторов и стандартных библиотек. Целесообразность использования библиотек (mkl, goto) зависит от приложения. В частности, для решения задач обращения матриц библиотека функций BLAS [5] хорошо оптимизирована, о чем свидетельствуют результаты тестов Linpack. Для данного примера проводились сравнения использования возможностей оптимизации компилятором непосредственно кода и использования библиотечных функций скалярного произведения векторов (DDOT) и умножения матриц (DGEMM). Использовались библиотеки mkl и goto. Результаты показывают, что в данном случае при правильном выборе размера блока код, оптимизированный компилятором, обеспечивает большую производительность, чем библиотечные функции. Поэтому при реализации программ желательно сравнивать возможности как компиляторов, так и библиотечных функций.
Отдельный вопрос – использование возможностей оптимизации компиляторов и стандартных библиотек. Целесообразность использования библиотек (mkl, goto) зависит от приложения. В частности, для решения задач обращения матриц библиотека функций BLAS [5] хорошо оптимизирована, о чем свидетельствуют результаты тестов Linpack. Для данного примера проводились сравнения использования возможностей оптимизации компилятором непосредственно кода и использования библиотечных функций скалярного произведения векторов (DDOT) и умножения матриц (DGEMM). Использовались библиотеки mkl и goto. Результаты показывают, что в данном случае при правильном выборе размера блока код, оптимизированный компилятором, обеспечивает большую производительность, чем библиотечные функции. Поэтому при реализации программ желательно сравнивать возможности как компиляторов, так и библиотечных функций.| Permanent link: http://swsys.ru/index.php?id=727&lang=en&page=article |
Print version Full issue in PDF (1.83Mb) |
| The article was published in issue no. № 2, 2008 | |
| Статья находится в категориях: Обработка данных, Программно-аппаратные средства | |
Perhaps, you might be interested in the following articles of similar topics:
- Комплексная разработка программно-аппаратных компонентов фильтра преобразователя частоты для работы в судовых сетях ограниченной мощности
- Методы сокращения количества уязвимостей в специальном программном обеспечении реального времени
- Генератор текста программ в исходном виде для систем реального времени
- Адаптивные нечеткие системы по таксономии класса FOREL
- Программная система исследований динамики технологических процессов формования химических волокон
Back to the list of articles