Journal influence
Bookmark
Next issue
A distributed platform for parallel training of DisANN artificial neural networksA distributed platform for parallel training of disann artificial neural networks
The article was published in issue no. № 3, 2013 [ pp. 99-103 ]Abstract:The article describes the process of design, development and implementation of distributed neural network learning system based on learning-by-block algorithm for feed-forward neural networks. Distributing occurs in the array of training vectors which is divided into several blocks, transmitted to computing nodes. Thus, the neural network training is parallelized within the same epoch. Since neural networks are resistant to errors, losses are not critical. To avoid synchroniza tion bottlenecks in the end of each epoch, training may be carried out with losses of blocks. When synchronizing and transit-ing to the next epoch only a certain percentage of used training blocks or predetermined processor time is required. Within each period loss in training is compensated with the weighted value of last successful result. The system is based on a previ-ously created Anthill open-source platform for grid-computing. Applying the concept of grid-computing, the ability of con-trolling through web-interface and free choice of libraries for neural networks simulation allowed creating a system with a high degree of flexibility and ease of use.
Аннотация:В данной работе описан процесс проектирования, реализации и внедрения системы распределенного обучения нейронных сетей на основе алгоритма learning-by-blockдля нейронных сетей прямого распространения. Распределе-ние происходит в рамках массива обучающих векторов, который разделяется на несколько блоков, а блоки в свою очередь передаются вычислительными узлами. Таким образом, обучение нейронной сети распараллеливается в рам-ках одной эпохи. Так как нейронные сети по принципу своей работы устойчивы к ошибкам, то потери блоков не критичны. Для избежания узких мест в момент синхронизации в конце каждой эпохи обучение может проводиться с потерями. При синхронизации и переходе к следующей эпохе необходимо и достаточно определенного процента ис-пользованных для обучения блоков или заданного объема процессорного времени. В рамках каждой эпохи потери в обучении компенсируются взвешенным значением последнегоуспешного результата. Система базируется на соз-данной ранее open-source платформе для проведения grid-вычислений Anthill. Применение концепции grid-вычислений, возможность управления через web-интерфейс и свободного выбора библиотек для моделирования нейронных сетей позволили создать систему, обладающую высокой степенью гибкости и простоты использования.
| Authors: (giangvmu@gmail.com) - , Russia, (akrasnoschekov@gmail.com) - , Russia | |
| Keywords: django, python, loosely coupled problems, neural network learning algorithms, error back-propagation learning, parallel training of neural networks, artificial neural networks, grid computing, distributed computing |
|
| Page views: 12837 |
Print version Full issue in PDF (13.63Mb) Download the cover in PDF (1.39Мб) |
Распределенные вычисления открыли новые пути приложениям, требующим больших вычислительных мощностей. Рост объемов данных обусловил практически повсеместное использование распределенных вычислений [1]. Вместе с тем применение распределенных вычислений для обучения искусственных нейронных сетей (ИНС) является относительно новой и мало исследованной задачей [2, 3]. Еще в 40-х годах прошлого века достижения нейробиологии позволили создать первую искусственную нейронную сеть, которая имитировала работу человеческого мозга. Но только через несколько десятилетий, с появлением современных компьютеров и адекватного ПО стала возможной разработка сложных приложений в области ИНС. Сегодня теория нейронных сетей – одно из наи- более перспективных направлений научных исследований. Этому способствовали сама природа параллельных вычислений и практически доказанная возможность адаптивного обучения нейронных сетей. C увеличением сложности задач, решаемых современной наукой, появляется необходимость во все больших вычислительных мощностях. Это требует серьезных инвестиций в модернизацию вычислительных систем. Однако в действительности уже имеющиеся ресурсы расходуются непродуктивно: так, компьютеры в научных организациях работают максимум на 10 % своей мощности, а серверы – на 30 % [3]. При рациональном использовании этих ресурсов можно выполнять существенные объемы вычислений. Решить задачу эффективного использования в глобальном масштабе ресурсов, принадлежащих одной или нескольким организациям, призвана технология grid-вычислений. Данные вычисления подтвердили свою значимость в науке такими проектами, как Boinc, EGEE, AntHill. Таким образом, растущая потребность в вычислительных мощностях и высокая степень интеграции распределенных вычислительных ресурсов делают создание платформы для обучения нейронных сетей приоритетной задачей. В данной работе изучены подходы к построению и параллельному обучению ИНС, раскрыты преимущества и недостатки каждой отдельной архитектуры, описана созданная распределенная вычислительная платформа для ресурсоемкого обучения нейронных сетей DisANN (Distributed Artificial Neural Network). Основные концепции DisANN В настоящее время распределенные вычис- лительные системы мало задействованы для ре- шения задач с применением нейронных сетей. Исследование существующих технологий распределенного обучения нейронных сетей [4–6] позволило сформулировать основные концепции для построения и функционирования программной платформы, удовлетворяющей актуальным потребностям в моделировании нейронных сетей. Использование свободных мощностей. Зачастую крупные организации имеют большое количество свободных гетерогенных вычислительных ресурсов. Применение распределенных вычислений обеспечит оптимальное использование ресурсов, делегируя обработку заданий свободным узлам. Волонтерские вычисления. Принадлежность всех вычислительных ресурсов к одной организации не является обязательным условием. Организации должны придерживаться некоторых общих правил при участии в системе, но в целом могут работать независимо. Таким образом, для решения одной общей задачи могут быть задействованы ресурсы нескольких организаций, а также любых заинтересованных лиц. Использование стандартных интерфейсов и протоколов. Кроссплатформенные приложения и протоколы позволяют легко расширять вычислительную сеть на все возможные типы вычислительных ресурсов, включая персональные компьютеры, а также некоторые мобильные устройства и высокопроизводительные системы. Масштабируемость. Вычислительные ресурсы не управляются централизованно. Следуя концепции REST, информация о текущем состоянии задачи не хранится на клиенте, поэтому в любой момент можно добавить и удалить ресурс из системы. Обмен по протоколу HTTP/HTTPS. Существует множество протоколов для передачи и приема данных, однако HTTP/HTTPS используется практически повсеместно. Обеспечить безопасность информации в сложных средах распределенных вычислений чрезвычайно трудно, но простой перевод сервера системы в режим HTTPS сразу снимает эту проблему. Высокие требования к качеству услуг. Упрощение заданий и некоторая степень избыточности позволяют эффективно распределить нагрузку и обеспечить вычисления с максимальной надежностью.
Свободный выбор архитектуры ИНС. Архитектуры ИНС крайне разнообразны, и для их применения к конкретной задаче зачастую требуется изменение не только параметров, но и самой модели. Поэтому система должна поддерживать модульную интеграцию программных библиотек, реализующих различные типы нейронных сетей. Потери данных. Так как ИНС по принципу своей работы являются устойчивыми к ошибкам, потери блоков не критичны. Более того, во избежание узких мест в момент синхронизации в конце каждой эпохи обучение может проводиться с потерями. Для синхронизации и перехода к следующей эпохе необходим и достаточен определенный процент использованных для обучения блоков или заданный объем времени процессора. В рамках каждой эпохи потери в обучении компенсируются взвешенным значением последнего успешного результата:
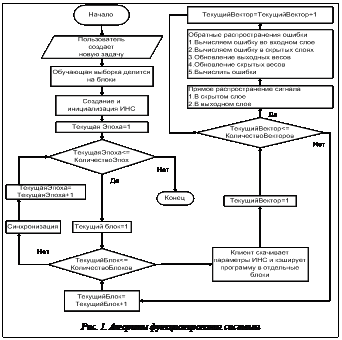
где i, j – индексы нейронов; k – номер текущей эпохи; g – номер последней успешной эпохи. Высокая скорость вычислений. Для разработки системы требуется простой и популярный в научной среде кроссплатформенный язык программирования. Исходный код программы должен быть минималистичным и легким в управлении и развитии. Поэтому основным языком разработки выбран Python. Код на Python несет обобщающую функцию, все критические задачи оптимизированы. Реализованы механизмы кэширования, оптимизированы запросы к БД, обмен изменениями весов ИНС происходит в бинарном формате, поддерживаются многопроцессорные системы. Разработка DisANN Руководствуясь описанными концепциями, авторы создали программную платформу DisANN с открытым исходным кодом [4]. Система реализована в виде клиент-серверной модели, управляемой посредством web-интерфейса, созданного на основе Django. Для иллюстрации работы системы рассмотрим пример решения задачи. Пользователь должен войти в web-интерфейс и загрузить файл с описанием структуры ИНС, а также файл с обучающей выборкой. Далее обучающая выборка разбивается на заданное количество блоков, которые вместе со структурой нейронной сети распределяются по вычислительным узлам. На каждом узле проходит обучение сети на основе полученного блока, и на сервер возвращаются бинарные изменения весов. В конце каждой эпохи сервер обновляет модель ИНС и снова рассылает ее клиентам (рис. 1). Введем следующие обозначения: Ni – размер входного слоя; Nh – размер скрытого слоя; No – размер выходного слоя; N – скорость; M – момент; Ai – входной вектор (a1, a2, …, ani); Ti – вектор выходных данных (t1, t2, …, tno). Прямое распространение сигнала · в скрытом слое:
· в выходном слое:
Обратное распространение ошибки. 1. Вычисляем ошибку в выходном слое:
2. Вычисляем ошибку в скрытых слоях:
3. Обновляем выходные веса:
4. Обновляем скрытые веса:
5. Вычисляем ошибки:
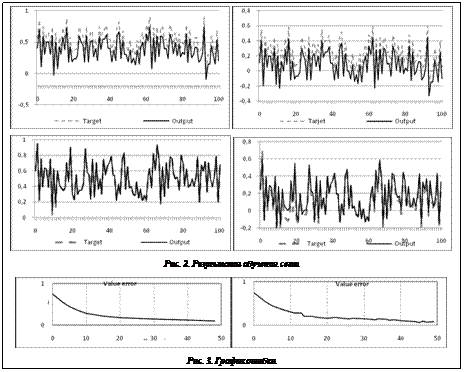
Результаты испытаний Было протестировано несколько обучающих выборок. Эффективность распределения обучения показана на рисунке 2. Обучающая выборка составила 10 000 векторов, вычисления производились на одной машине и 10 компьютерах. Одна и та же нейронная сеть в случае обучения на одном компьютере не позволяет добиться желаемого значения ошибки (слева), в то же время на 10 компьютерах сеть обучается в полной мере (справа). Следует отметить, что в среде с потерями данных функция ошибки заведомо не будет гладкой (рис. 3).
Практическое применение Система DisANN используется для решения обратных задач механики твердого тела на кафедре «Информационные технологии» Донского государственного технического университета. Система показала высокую эффективность при обучении сетей размером до 10 000 нейронов (рис. 5). Таким Система может быть применена для создания импровизированного дата-центра и для обеспечения исследователей расчетами при минимальных временных затратах на развертывание и функционирование. Авторы выражают глубокую признательность д.т.н., профессору Соболю Борису Владимировичу за руководство проведением исследования и разработки. Литература 1. Distributed computing. URL: http://en.wikipedia.org/wiki/ Distributed_computing (дата обращения: 30.07.2012). 2. Haykin S., Neural Network a comprehensive foundation (2nd ed.), Prentice Hall, 1998, 842 p. 3. Sundararajan N., Saratchandran P., Parallel architectures for Artificial Neural Networks, Wiley-IEEE Computer Society Press, 1998, 412 p. 4. GitHub. URL: http://github.com/s74/ant2 (дата обращения: 21.04.2012). 5. Distributed computing on internet. URL: http://fgouget. free.fr/distributed/index-en.shtml (дата обращения: 21.04.2012). 6. Lisandro Daniel Dalcin, Techniques for High-Performance distributed computing in computational fluid mechanics, CIMEC Document Repository, 2008, 102 p. Referenses 1. Distributed computing, available at: http://en.wikipedia. org/wiki/Distributed_computing (accessed 30 July 2012). 2. Haykin S., Neural Network a comprehensive foundation, 2nd edition, Prentice Hall, 1998. 3. Sundararajan N., Saratchandran P., Parallel architectures for Artificial Neural Networks, Wiley-IEEE Computer Society Press, 1998. 4. GitHub, available at: http://github.com/s74/ant2 (accessed 21 April 2012). 5. Distributed computing on internet, available at: http:// fgouget.free.fr/distributed/index-en.shtml (accessed 21 April 2012). 6. Dalcin L.D., Techniques for High-Performance distributed computing in computational fluid mechanics, CIMEC Document Repository, 2008. |
 Минималистичный подход к распределению нейронных сетей. Для решения широкого круга задач необходимо распределение не самой нейронной сети, а только обучающей выборки. Массив обучающих векторов разделяется на несколько блоков, а блоки, в свою очередь, распределяются между вычислительными узлами. Таким образом, обучение ИНС распараллеливается в рамках одной эпохи. Такой процесс обучения относится к классу слабосвязанных задач.
Минималистичный подход к распределению нейронных сетей. Для решения широкого круга задач необходимо распределение не самой нейронной сети, а только обучающей выборки. Массив обучающих векторов разделяется на несколько блоков, а блоки, в свою очередь, распределяются между вычислительными узлами. Таким образом, обучение ИНС распараллеливается в рамках одной эпохи. Такой процесс обучения относится к классу слабосвязанных задач.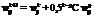 ,
,  , ah – выходной вектор скрытого слоя;
, ah – выходной вектор скрытого слоя;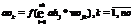 , ao – выходной вектор сети.
, ao – выходной вектор сети.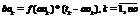 , где bo – значение ошибки, используемой для изменения выходных весов.
, где bo – значение ошибки, используемой для изменения выходных весов.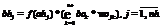 , где bh –значение ошибки, используемой для изменения скрытых весов.
, где bh –значение ошибки, используемой для изменения скрытых весов.
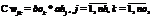 где wo – вес, соединяющий скрытый нейрон j с k в выходном слое сети.
где wo – вес, соединяющий скрытый нейрон j с k в выходном слое сети.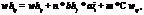
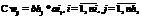 где wh – вес, соединяющий входной нейрон j с k в скрытом слое сети.
где wh – вес, соединяющий входной нейрон j с k в скрытом слое сети.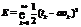 , где E – суммарная ошибка (для одной эпохи).
, где E – суммарная ошибка (для одной эпохи).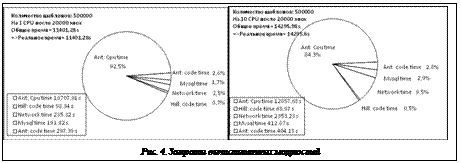 При распределении заданий между вычислительными узлами небольшой процент мощности тратится на обеспечение функционирования системы (рис. 4). Время отправки/получения данных будет больше, но итоговое время обучения сети во много раз меньше, чем в случае обучения на одной машине.
При распределении заданий между вычислительными узлами небольшой процент мощности тратится на обеспечение функционирования системы (рис. 4). Время отправки/получения данных будет больше, но итоговое время обучения сети во много раз меньше, чем в случае обучения на одной машине.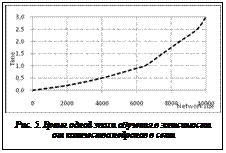 образом, в результате проведенного исследования была успешно разработана програм- мная платформа, которая позволяет реализовать рапределенное обучение нейронных сетей. Пользователи могут подключать собственные модели нейронных сетей. Программа оптимизирована с точки зрения производительности, функциональности и надежности.
образом, в результате проведенного исследования была успешно разработана програм- мная платформа, которая позволяет реализовать рапределенное обучение нейронных сетей. Пользователи могут подключать собственные модели нейронных сетей. Программа оптимизирована с точки зрения производительности, функциональности и надежности.| Permanent link: http://swsys.ru/index.php?id=3567&lang=en&page=article |
Print version Full issue in PDF (13.63Mb) Download the cover in PDF (1.39Мб) |
| The article was published in issue no. № 3, 2013 [ pp. 99-103 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Аналитическая модель оценки производительности распределенных систем
- Построение системы технического зрения для выравнивания содержимого упаковок дельта-манипулятором на пищевом производстве
- Модель анализа и прогнозирования технологических параметров для процесса электронно-лучевой сварки
- Интегрированная инструментальная среда организации проблемно-ориентированных распределенных вычислений
- Применение средств моделирования нейросетей для анализа предаварийных ситуаций на буровых
Back to the list of articles