Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: Vinogradov G.P. (wgp272ng@mail.ru) - Tver State Technical University, Tver, Russia, Ph.D, () - | |
| Keywords: self-organization, neural network, render, fuzzy sets, clusterization |
|
| Page views: 19253 |
Print version Full issue in PDF (4.72Mb) |
В последнее время возрос интерес к разработке гибридных кластерных процедур, сочетающих кластерный анализ с другими методами анализа данных [1–3]. В работе [4] предложена схема гибридной кластеризации, использующая процедуры конкуренции и кооперации, что позволяет с высокой степенью точности определять количество кластеров в условиях слабой выполнимости условий линейной разделимости. Уточнение результатов, полученных с помощью этого метода, достигается путем применения процедур кластеризации на базе нечетких отношений и технологии Visual Mining для получения субъективных оценок качества от исследователя [5]. Для проверки качества описанных в [4, 5] алгоритмов кластеризации и сравнения их с аналогами использовался стандартный тест, известный как задача об ирисах Фишера. Для каждого экземпляра ириса известны 4 параметра: длина чашелистика, ширина чашелистика, длина лепестка, ширина лепестка. Пятая переменная, целевая, обозначает класс (вид) и принимает значения: 1 – setosa, 2 – versicolor, 3 – virginica.
Таблица 1
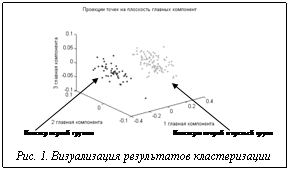
Анализ графиков функций принадлежности ирисов найденным кластерам, рассчитанных после уточнения координат центров алгоритмом FCM, показал высокое качество полученных вариантов кластеризации, хотя истинное количество классов равно трем. По результатам работы алгоритма FCM для первого варианта были рассчитаны значения критериев оценки качества: коэффициент четкости – 0,9973, индекс четкости – 0,0095, энтропия – 0,0096, нормализованная энтропия – 0,0137, модифицированная энтропия – 0,0650, компактность – 0,9945, эффективность – 68004,03. Значения показателя четкости и индекса четкости близки к единице и к нулю соответственно. Это указывает на четкое разбиение на кластеры. Значения энтропийных показателей близки к нулю, а показателя компактности и изолированности к единице. Это говорит о том, что найденные кластеры компактны и хорошо отделимы. Если значение индекса эффективности велико, найдено оптимальное количество кластеров. То есть по значениям формальных критериев можно сказать, что качество варианта кластеризации хорошее и, следовательно, нет объективных причин по формальным критериям отказываться от полученного варианта кластеризации. Полученные результаты показали: формальные методы, использующие только метрические меры сходства объектов, не позволяют выявить истинное разбиение множества объектов на кластеры. Для этого нужна дополнительная информация. Источником такой информации является эксперт, который знает, что данные содержат сведения о трех типах ирисов и что versicolor – это гибрид setosa и virgnica. Для получения этой информации была выполнена визуализация результатов кластеризации по результатам применения метода главных компонент. Это позволило отобразить результаты кластеризации в трехмерном пространстве и создало основу для получения субъективных оценок о качестве кластеризации (рис. 1). Визуализация варианта кластеризации показала, что ирисы первого кластера представляют компактную группу и хорошо отделимы от ирисов второй и третьей групп. Ирисы, принадлежащие 2-му и 3-му классам, плохо отделимы друг от друга. Исходя из анализа критериальных оценок и визуальной субъективной оценки, экспертом была дана оценка качества «плохо», так как данное решение не соответствует его представлениям о виде структуры исходных данных. Результат работы алгоритма FCM в случае 5 кластеров представлен в таблице 2. Таблица 2
По значениям критериев оценки качества кластеризации: коэффициент четкости – 0,6639, индекс четкости – 0,5674, энтропия – 0,5870, нормализованная энтропия – 0,3526, модифицированная энтропия – 0,9986, компактность – 0,5799, эффективность – 44974,94 можно сказать, что произведенное разбиение хуже, чем в предыдущем варианте. Анализ значений координат центров кластеров показал, что 3-й и 4-й центры находятся достаточно близко друг к другу. То же можно сказать о 2-м и 5-м найденных центрах. Это позволило эксперту сделать вывод о том, что существуют 3 центра, то есть 3 кластера, соответствующих 3 классам ирисов.
Для получения оценок об истинном количестве кластеров алгоритм разностного группирования был заменен алгоритмом на основе конкуренции и кооперации нейронов [4]. Параметрами для его запуска служит количество нейронов. Для данной задачи первоначальное количество нейронов равнялось 9. Полученное решение приведено в таблице 3. Таблица 3
Как видно из таблицы, алгоритм нашел верное количество кластеров – 3. Если сравнить координаты центров, найденные указанным алгоритмом, с координатами центров первого варианта кластеризации, можно сделать вывод о том, что центры всех вариантов кластеризации для данных, относящихся к первому классу, очень близки. Это говорит о том, что данный алгоритм легко распознает хорошо сгруппированные данные. Что касается данных 2-го кластера, то алгоритм предложил разбиение его на два класса; это верно с точки зрения семантики задачи. Алгоритм FCM позволил уточнить полученное решение и найти степени принадлежности данных различным классам. Графики функций принадлежности приведены на рисунке 2. Анализ графиков показал, что данные, относящиеся к первому классу, хорошо распознаны. Функции принадлежности для второго и третьего кластеров ведут себя скачкообразно. Это указывает на некоторый процент пересечения данных, относящихся ко 2-му и 3-му классам ирисов. На втором и третьем графиках также видно, что первые девять ирисов третьего класса отнесены алгоритмом FCM ко второму классу, что является ошибкой. Для дальнейшего анализа варианта кластеризации были вычислены значения формальных критериев: коэффициент четкости – 0,7270, индекс четкости – 0,4673, энтропия – 0,4769, нормализованная энтропия – 0,4254, модифицированная энтропия – 0,4039, компактность – 0,5905, эффективность – 54812,61. Значение показателя четкости указывает на процент пересечения кластеров. Значение индекса четкости, равного 0,4039, указывает на нечеткое разбиение на кластеры. По значениям энтропийных показателей, показателя компактности и изолированности можно сделать вывод о том, что не все кластеры компактны и не все данные хорошо разделимы. Значение индекса эффективности выше, чем при варианте с пятью кластерами, и ниже, чем при варианте с двумя кластерами. Это означает, что найденный вариант кластеризации может быть достаточно близким к оптимальному. В отличие от предыдущих вариантов кластеризации на данном этапе визуализация решения необходима для оценки качества кластеризации и определения возможности улучшения решения. По проекциям данных на плоскость первых двух главных компонент установлено, что с 9 ошибками найдено распределение ирисов по трем классам. Уменьшение ошибки связано с корректировкой координат центров кластеров. Направление корректировки определялось по оценкам эксперта путем сравнения оценок результатов кластеризации. Новые координаты центров представлены в таблице 4. Таблица 4
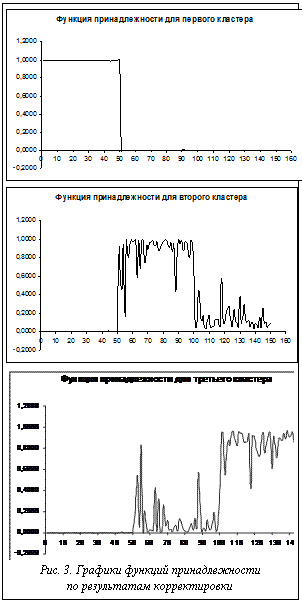
Графики функций принадлежности приведены на рисунке 3. По поведению функции принадлежности, представленной на первом графике, можно сказать, что первый кластер хорошо отделим от двух других – значения степеней принадлежности практически всех данных первого класса равны единице. На втором и третьем графиках значения степеней принадлежности практически всех данных первого класса равны нулю. По поведению функций принадлежности второго и третьего кластеров можно сделать вывод о том, что они имеют общие объекты и данные, принадлежащие им, все еще полностью не разделены. Значения формальных параметров, соответствующие варианту кластеризации, говорят об улучшении результатов кластеризации: коэффициент четкости – 0,8747, индекс четкости – 0,2152, энтропия – 0,2195, нормализованная энтропия – 0,1958, модифицированная энтропия – 0,2223, компактность – 0,8121, эффективность – 61571,11.
По сравнению с предыдущим вариантом значение показателя четкости приблизилось к единице, значения энтропийных показателей уменьшились. Также улучшились значения других критериев. Однако значение индекса четкости уменьшилось; это говорит о том, что разбиение стало менее четким. Визуальное представление результатов кластеризации показало наличие четырех ошибок для полученных оценок координат центров кластеров и значений функций принадлежности объектов каждому кластеру. Качество данного варианта кластеризации оказалось достаточно неплохим (ошибка составила 2,7 %). Сравнивая графики функций принадлежности предыдущего и текущего вариантов кластеризации, можно сказать, что система позволила найти более качественное решение.
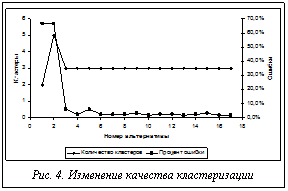
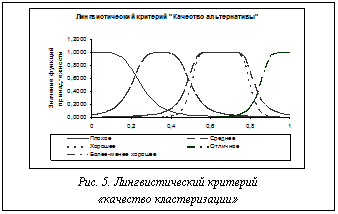
В результате продолжения вычислительного эксперимента было найдено 15 (вместе с уже рассмотренными) альтернатив разбиения исходных данных на 3 кластера. По результатам расчетов построены графики процента ошибок и количества кластеров для всех вариантов кластеризации (рис. 4). Их анализ показал, что количество кластеров стабилизировалось и наблюдается сходимость числовой последовательности, содержащей значения процента ошибки. Для выбора лучшей альтернативы по каждому варианту кластеризации рассчитаны оценки по формальным критериям, нечеткие оценки обобщенного критерия по методике и субъективные оценки результатов кластеризации, приведенной в работе [5]. Из множества найденных решений отбирались те альтернативы, качество которых превышало заданный экспертом уровень. Для определения числового эквивалента качества результатов кластеризации введен лингвистический критерий «качество кластеризации» как универсальное множество, для которого использован интервал изменения значений обобщенного критерия. Терм-множества – лингвистические оценки эксперта качества вариантов кластеризации. Функции принадлежности термов показаны на рисунке 5.
Для выбора альтернативы (альтернатив) приемлемого качества были найдены нечеткие оценки по функциям принадлежности лингвистического критерия «качество альтернативы» для каждой альтернативы. Для определения недоминируемых альтернатив экспертом был выбран уровень значимости, равный 0,5. Альтернативы с нечеткими оценками, превышающими этот уровень, считались недоминируемыми. Таким образом, для дальнейшей оценки отобраны 6 альтернатив (табл. 5). Таблица 5
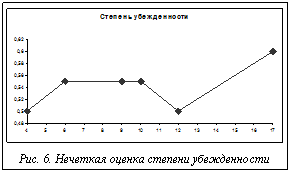
Для выбора среди них оптимального варианта было построено нечеткое множество взаимно недоминируемых альтернатив. Соответствие значений функции принадлежности нечеткому множеству взаимно недоминируемых альтернатив следующее: 0,5 – 4; 0,55 – 6; 0,55 – 9; 0,55 – 10; 0,5 – 12; 0,6 – 17. По этим данным построен график степени убежденности эксперта в том, что рассматриваемая альтернатива является наилучшей (рис. 6).
Таким образом, оптимальной оказалась альтернатива с номером 17. Данный вариант кластеризации предлагает разбиение исходной совокупности данных на 3 кластера. Ошибка данного варианта составила 2 %, а обобщенная оценка максимальна среди оценок вариантов с минимальным количеством ошибок. Координаты центров данного варианта представлены в таблице 6. Таблица 6
Сравнение работы предложенного алгоритма кластеризации с результатами работы аналогов показало, что количество ошибок является сопоставимой величиной и колебалось на уровне от 1 до 3 %, но при этом эксперт получал возможность легко интерпретировать полученные результаты. Существенным отличием явилось то, что количество признаков, по которым производилась кластеризация, не увеличивалось, то есть их было 4. В других продуктах добавлялись дополнительные признаки (по крайней мере один – указывался класс ириса), что естественно увеличивало время работы системы и стоимость анализа. Кроме того, в большинстве практических задач на начальном этапе трудно обосновать введение дополнительных атрибутов, что делает проблематичным интерпретацию полученного разбиения. Литература 1. Батыршин И.З., Климова А.С. Гибридная реляционная кластеризация и визуализация данных // НСМВ-2006: тр. Всерос. научн. конф. «…». М.: Физматлит, 2006. С. 193–209. 2. Виноградов Г.П., Мальков А.А. Кластеризация на основе нечетких отношений и технологии Visual Mining // Системы управления и информационные технологии. 2008. № 1.1 (31). С. 137–141. 3. Pedrycz W. Knowledge-Based Clustering. From Data to Information Granules. Wiley-Interscience, 2005, p. 336. 4. Виноградов Г.П., Мальков А.А. Модели поиска структур данных на основе конкуренции и кооперации. Управление большими системами: сб. тр. Вып. 22. М.: ИПУ РАН, 2008. 5. Виноградов Г.П., Мальков А.А. Эволюционные методы кластеризации, использующие нечеткие отношения и субъективные оценки // Интеллект. системы. Интеллект. САПР: сб. тр. Междунар. науч.-технич. конф. М.: Физматлит, 2008. Т. 1. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Сравнение разработанного метода (алгоритма) проводилось с базовым алгоритмом нечеткой кластеризации FCM, идея которого положена в основу известных пакетов интеллектуального анализа данных: Neural Planner, BrainMaker, MPIL в сочетании с алгоритмом разностного группирования. Последний необходим для определения количества кластеров. Прогонка алгоритма разностного группирования позволила получить два варианта количества и первоначального распределения кластеров: первый вариант – 2 кластера, второй вариант – 5 кластеров. Результаты работы этого алгоритма показаны в таблице 1.
Сравнение разработанного метода (алгоритма) проводилось с базовым алгоритмом нечеткой кластеризации FCM, идея которого положена в основу известных пакетов интеллектуального анализа данных: Neural Planner, BrainMaker, MPIL в сочетании с алгоритмом разностного группирования. Последний необходим для определения количества кластеров. Прогонка алгоритма разностного группирования позволила получить два варианта количества и первоначального распределения кластеров: первый вариант – 2 кластера, второй вариант – 5 кластеров. Результаты работы этого алгоритма показаны в таблице 1.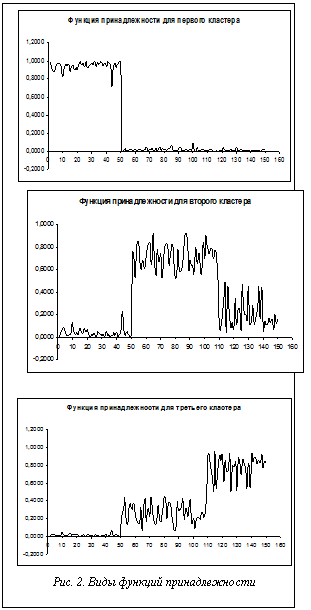
| Permanent link: http://swsys.ru/index.php?id=2271&lang=en&page=article |
Print version Full issue in PDF (4.72Mb) |
| The article was published in issue no. № 2, 2009 |
Perhaps, you might be interested in the following articles of similar topics:
- Система реконструкции моделей материалов по фотоизображениям
- Моделирование принятия решений интеллектуальным агентом
- Структуризация сущностей естественного текста с использованием нейронных сетей для генерации трехмерных сцен
- Разработка базы данных и конвертера для извлечения и анализа специализированных данных, получаемых с медицинского аппарата
- Моделирование аутентификации пользователей по динамике нажатий клавиш в промышленных автоматизированных системах
Back to the list of articles