Journal influence
Bookmark
Next issue
Developing predictive analytics models for industrial equipment failures
Abstract:The paper describes new approaches to building a model for predictive analytics of industrial equipment failures. The relevance of the study is due to the need to identify failures that lead to a decrease in operating efficiency or downtime of large production lines at an industrial enterprise in advance. The study examines modern approaches, which use machine learning to solve similar problems, and describes their advantages and disadvantages in detail. Data for training models was obtained from PJSC Severstal and include information on sensor readings measuring currents, temperatures, pressure and vibrations for six exhausters over three years. Training and testing involved only technical locations with faults during the analyzed period. Due to the complex relationship between sensor readings and exhauster condition, it was decided to create a predictive model based on “soft voting” between three algorithms with different classification approaches: a convolutional neural network, logistic regression and a support vector machine. The proposed approach is based on the high-level Python programming language using the Anaconda distribution. The paper describes the procedure for performing the research, presents block diagrams of the developed algorithms and their detailed description. The authors carried out comprehensive testing of the developed software that implements the fault prediction model. The study results confirm the performance of the proposed model for predicting failures of equipment technical components, which can be adapted for predictive analytics of failures of a large number of types of industrial equipment at large enterprises in metallurgical, chemical and other industries.
Аннотация:В статье описаны новые подходы к построению модели предиктивной аналитики неисправностей промышленного оборудования. Актуальность исследования обусловлена необходимостью заблаговременно идентифицировать неисправности, приводящие к снижению эффективности работы или простоям крупных производственных линий промышленного предприятия. В рамках исследования были изучены современные подходы, использующие машинное обучение для решения схожих задач, подробно описаны их достоинства и недостатки. Данные для обучения моделей включают сведения о показаниях датчиков, измеряющих токи, температуры, давления и вибрации, для шести эксгаустеров за три года. Для обучения и тестирования были отобраны только техместа с наличием неисправностей за анализируемый период. В связи со сложной взаимосвязью между показаниями датчиков и состоянием эксгаустера было принято решение о создании предсказательной модели, основанной на мягком голосовании между тремя алгоритмами, имеющими различные подходы к классификации: сверточная нейронная сеть, логистическая регрессия и метод опорных векторов. Предложенный подход реализован с помощью высокоуровневого языка программирования Python c использованием дистрибутива Anaconda. Описан порядок выполнения исследования, представлены блок-схемы разработанных алгоритмов и их подробное описание. Про-ведено всестороннее тестирование разработанного программного обеспечения, реализующего модель прогнозирования неисправностей. Результаты исследования подтверждают работоспособность предлагаемой модели прогнозирования неисправности технических узлов оборудования, которая может быть адаптирована для предиктивной аналитики неисправностей большого числа типов промышленного оборудования крупных предприятий металлургической, химической и других отраслей промышленности.
| Authors: Chernukhin, A.V. (chernukhin.a.v@muctr.ru) - Mendeleev University of Chemical Technology of Russian (Postgraduate Student), Moscow, Russia, , Bogdanova, E.A. (eabogdanova.bioinf@gmail.com) - Lomonosov Moscow State University (Postgraduate Student), Moscow, Russia, , Savitskaya T.V. (savitsk@muctr.ru) - D. Mendeleev University of Chemical Technology of Russian Federation (Professor), Moscow, Russia, Ph.D | |
| Keywords: fault prediction, industrial equipment, neural network, machine learning, predictive analytics, data intelligent analysis, mathematical and computer modeling |
|
| Page views: 2305 |
PDF version article |
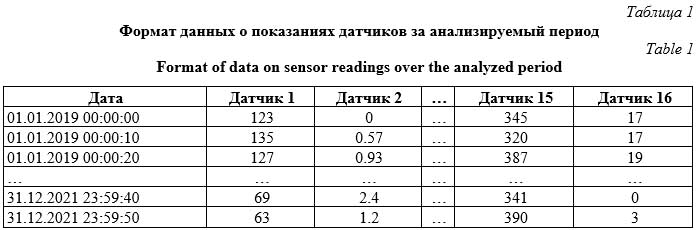
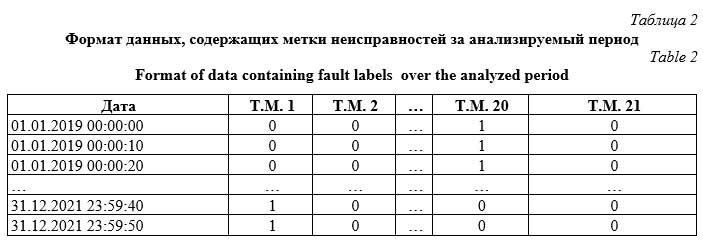
Введение. Проблема возникновения неисправностей промышленного оборудования, приводящих к снижению эффективности работы или к простоям крупных производственных линий, а следовательно, к убыткам, актуальна во всем мире [1, 2]. Вместе с тем активно продолжается автоматизация всех отраслей промышленного производства, которая обусловливает развитие информационно-технических систем предприятия [3], а значит, систем сбора, хранения и мониторинга состояния оборудования в режиме реального времени. При этом эксперты в области промышленных информационных систем сходятся во мнении, что аккумулированные большие объемы данных могут использоваться для прогнозирования неисправностей задолго до их возникновения [4, 5]. Для этого необходимо построение отдельной подсистемы предиктивной аналитики, исполь- зуемой для гибкого планирования технического обслуживания и ремонта [6]. Методы прогнозирования на основе классического машинного обучения широко используются в области диагностики и прогнозирования неисправностей оборудования благодаря хорошей интерпретируемости результатов обучения, относительно невысоким требованиям к вычислительным ресурсам и широкому выбору подходов, которые обеспечивают разносторонний анализ данных [7, 8]. Хотя классические алгоритмы машинного обучения хорошо показывают себя в диагностике и прогнозировании неисправностей, они уступают нейросетевым алгоритмам в идентификации сложных взаимосвязей между показаниями большого числа датчиков и состоянием оборудования [9, 10]. Было проведено большое количество исследований, направленных на разработку алгорит- мов на основе нейронных сетей [11], но в по-давляющем большинстве случаев диагностика в них осуществляется только для одного технического места (подшипник, ротор и др.), что говорит о сложности или невозможности масштабирования таких подходов [12, 13]. В подобных работах для обучения и тестирования используются наборы данных с большим количеством примеров неисправностей, за счет чего достигается высокая точность предсказания (accuracy = 0.8–0.9). Однако возникновение неисправности – достаточно редкое явление в работе промышленного оборудования, в связи с чем часто отсутствует возможность накопления обширной библиотеки отказов [14]. Это является основной трудностью в диагностике неисправной работы в условиях реального производства с помощью нейронных сетей, так как они в таких случаях проявляют склонность к переобучению [15, 16]. Соответственно, в системе предиктивной аналитики, работающей в режиме реального времени, необходимо использовать как методы классического машинного обучения, так и нейросетевые алгоритмы, за счет чего будут нивелированы их недостатки, связанные с переобучением в условиях небольшого количества данных о неисправностях [17, 18]. Для повышения точности предсказания между моделями в ансамбле будет проводиться так называемое мягкое голосование. Модель необходимо обучать на данных с долей неисправной работы менее 15 % по каждому техническому месту, а раннее прогнозирование возникновения неисправностей для всех ключевых технических мест следует осуществлять одновременно. Целью данного исследования является разработка комплексной модели, позволяющей прогнозировать неисправности промышленного оборудования с учетом специфики реальных промышленных данных. Ее отличительной особенностью является использование ансамблевого подхода к предсказанию неисправностей, основанного на проведении операции голосования между методами классического машинного обучения и нейросетевым алгоритмом, что позволяет максимально разносторонне рассмотреть признаковое пространство и выявить наиболее важные свойства. Разработанное ПО позволит на основе текущих данных о состоянии оборудования, получаемых с датчиков, заблаговременно идентифицировать зарождающиеся неисправности. Для обучения моделей использованы данные, полученные от ПАО «Северсталь», в ка- честве оборудования выступают эксгаустеры агломерационной машины – центробежные наг- нетатели, осуществляющие просос воздуха через слой шихты. Предобработка данных В наборе обучающих данных присутствуют сведения о показаниях датчиков для шести эксгаустеров за три года (с 01.01.2019 по 31.12.2021) в десятисекундных интервалах. Формат данных представлен в таблице 1. Датчики измеряют такие показания состояния оборудования, как токи (амперы), температуры (градусы Цельсия), давления (КПа), вибрации (мм/с). Всего проводился анализ показаний 16 датчиков.
Количество и набор технических мест отличались для каждого из эксгаустеров (от 20 до 35). Для обучения и тестирования были отобраны техместа с наличием неисправностей за анализируемый период – маслоохладитель, подшипник опорный, вибропреобразователь, электроаппаратура, электродвигатель, улита, корпус, ротор. Предобработка показаний датчиков включала в себя следующие этапы. · Удаление выбросов. Производились обнуление отрицательных показаний датчиков и уменьшение амплитуды значений, превышающих среднее более чем в сто раз (так как подобные значения не являются нормальными показаниями датчиков и негативно сказываются на обучении). · Приведение данных к часовым интервалам из десятисекундных. Показания с шагом в 10 секунд являются избыточными и неоптимальными для обучения предсказательного алгоритма в связи с зашумленностью данных и большим объемом занимаемой памяти (необходимы хранение и работа с таблицей, содержащей 9 460 800 строк для каждого эксгаустера). Для дальнейшей работы для каждого из часовых интервалов (360 строк) рассчитывались статистические характеристики, такие как среднее, медиана, максимальные и минимальные значения. В дальнейшем именно эти значения использованы в качестве признаков при обучении модели. · Стандартизация и замена пропущенных значений. В связи с различной природой показаний датчиков производилась их стандартизация. Для этого рассчитывались обобщенное для всех эксгаустеров среднее значение и стандартное отклонение для каждого датчика, которые и использовались для стандартизации. Оставшиеся пропущенные значения заполнялись путем интерполяции. · Добавление новых признаков. Для получения информации об отклонении показаний датчиков за текущий час от показаний за предыдущие сутки рассчитывалась разность между средними значениями за эти периоды. Полученные изменения в дальнейшем также использовались в качестве признаков, поскольку позволяют не только учитывать информацию о локальных изменениях состояния системы, но и выявлять отклонения от состояния за более долгий промежуток времени. Весь набор данных состоит из 26 280 векторов, характеризующих часовые интервалы для шести эксгаустеров. Для тренировочного датасета отбирались интервалы для каждого эксгаустера, содержащие неисправности, при их отсутствии – фрагмент со штатным состоянием. Для валидации отбирались интервалы, следующие после отобранных для обучения и содержащие хотя бы одну продолжительную (более 3 суток) неисправность из всех эксгаустеров. В качестве тестового набора отбирались самые поздние интервалы, содержащие неисправности. В связи с тем, что периоды неисправного состояния оборудования для разных технических мест не совпадали, для каждого из них разделение происходило индивидуально, с учетом причин, повлекших за собой неисправность. Архитектура предсказательной модели
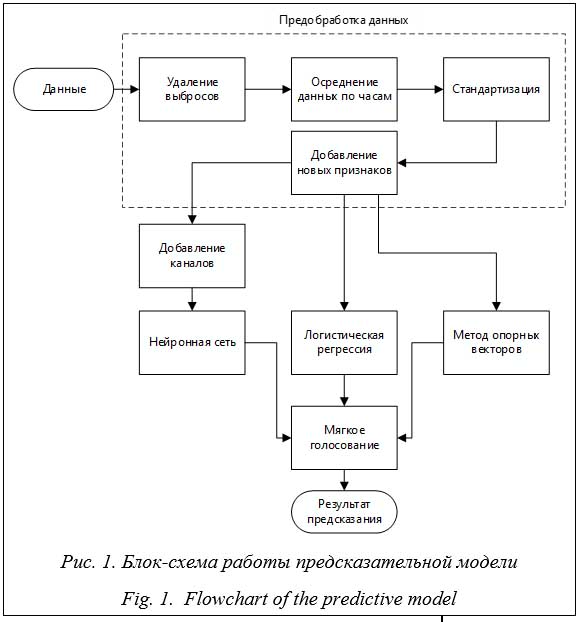
P1 = wa pa1 + wbpb1 + wcpc1, где P1 – итоговая вероятность принадлежности объекта к классу 1 (неисправность); pa1, pb1, pc1 – вероятности принадлежности объекта к классу 1, предсказанные тремя отдельными алгорит- мами; wa , wb, wc – веса, присваиваемые прогнозам отдельных алгоритмов. Для голосования использованы сверточная нейронная сеть, логистическая регрессия и метод опорных векторов. Выбор обусловлен низкой корреляцией их предсказаний друг с другом, составляющей менее 0.6, с относительно высоким качеством предсказания для большей части анализируемых технических мест (значение индекса Жаккара выше 0.5). Для логистической регрессии выбран базовый алгоритм оптимизации (LBFGS), максимальное количество итераций – 2 000 (что обусловлено большим количеством признаков). Метод опорных векторов обучался с использованием ядра rbf (Radial Basis Function) в связи с нелинейной разделимостью объектов в анализируемом наборе данных. Данные для моделей подавались на вход в виде векторов размера 96 (по 6 признаков для каждого из 16 датчиков), ответом являлась метка 0 или 1 в случае неисправности в течение часа, описываемого вектором признаков.
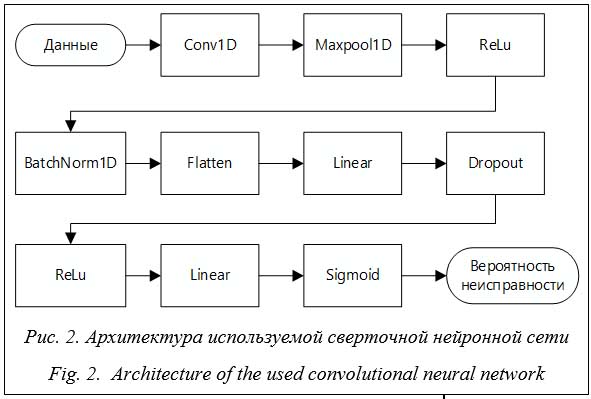
· Сверточный слой (Conv1D). Выполняет функции обобщения признаков в каналах и выявления значимых паттернов с увеличением числа каналов с 6 до 32. В качестве каналов используются статистические ха- рактеристики, рассчитанные для показателей каждого из 16 датчиков, в частности, среднее, медиана, максимальное и минимальное значения за час, а также разность между средним и медианой за час и за месяц. В связи с размером входного тензора выбран размер ядра свертки, равный 3. После сверточного слоя располагается слой подвыборки по максимальному значению (MaxPooling), который уменьшает в два раза размер тензора. В качестве функции активации использовалась выпрямленная линейная функция активации (ReLu). · Два полносвязных слоя (Linear) с уменьшением количества каналов (100, 1). Для первого слоя использовалась функция активации ReLu. В последнем слое непосредственно происходит предсказание наличия неисправности и используется сигмоидная функция активации (Sigmoid), которая выводит вероятность принадлежности объекта к классу 1 (наличие неисправности). Таким образом, на вход алгоритм принимает 4D-тензор размера 6×16, на выходе получается одно число, отражающее вероятность наличия неисправности за час, который описывается входным тензором. В целях нормализации и регуляризации после сверточных слоев использовалась пакетная нормализация (Batch Normalization), а после первых двух полносвязных слоев применялся метод прореживания (Dropout) со значением отсева 0.3 (из-за наличия пакетной нормализации значение выбрано меньше стандартного 0.5). В качестве оптимизатора был выбран оптимизатор Адама. Выбор обусловлен его эффективностью и возможностью добавления L2 регуляризации (параметр weight_decay), которая необходима для ограничения значения весов для признаков, что препятствует переобучению и способствует поиску общих закономерностей. В результате подбора гиперпараметров (настраиваемых вручную параметров обучения) использована скорость обучения, равная 0.0001, и weight_decay = 0.001. Для расчетаошибки применялась функция потерь BCELoss, оптимальная для решения задачи бинарной классификации. При оптимизации также подбирался размер пакета (batch size), оказывающий влияние на эффективность BatchNorma- lization и на продуктивность обучения. Исходя из размера обучающей выборки выбран batch size = 16. Обучение проводилось в течение 30 эпох, сохранялась модель с наименьшим значением функции потерь на валидационном наборе данных. Метрикой качества выступает индекс Жаккара, рассчитанный по формуле
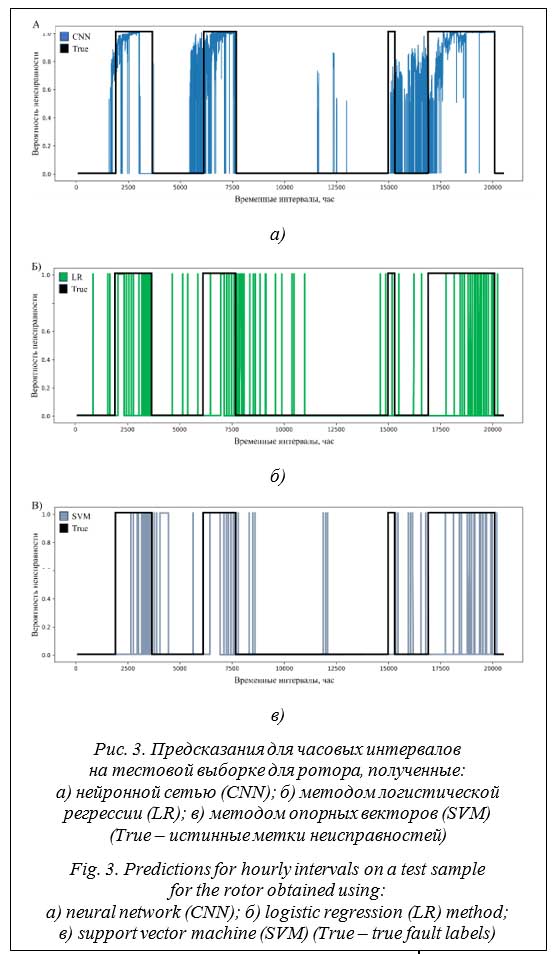
где J – индекс Жаккара; TP – истинно положительные значения из матрицы путаницы; FP – ложно положительные; FN – ложно отрицательные. Выбор данной метрики обусловлен более объективной работой с наборами данных, содержащими низкую долю одного из классов. Программное обеспечение разработано на высокоуровневом языке программирования Python c использованием дистрибутива Ana- conda, включающего набор свободных библиотек, используемых при работе с данными и в машинном обучении. Описание и сравнение полученных результатов На первом этапе работы были обучены предсказательные модели отдельно для каждого технического места. В результате обучения нейронной сети получены вероятности неисправности в каждый момент времени. Для идентификации неисправностей в разных техместах индивидуально подбирались пороги принятия решения. На рисунке 3а представлено распределение вероятностей наличия неисправности на тестовой выборке для ротора (в качестве порога взято значение 0.5), при этом индекс Жаккара равен 0.6 (http://www. swsys.ru/uploaded/image/2024-2/5.jpg). В тестовых временных интервалах для трех эксгаустеров, объединенных в общий тестовый набор, наблюдаются три продолжительные неисправности и одна более короткая (рис. 3а). Можно заметить, что в трех случаях модель начинала присваивать высокую вероятность развития неисправности заранее, до официального начала, обозначенного оператором. Это, с одной стороны, отрицательно повлияло на значение метрики качества, а с другой, является положительным моментом, позволяя диагностировать начало развития неисправности до того, как это явным образом скажется на работе эксгаустера и будет замечено оператором. Однако одна из неисправностей не была диагностирована, что может быть связано с причиной, слабо представленной в обучающем наборе данных.
Благодаря использованию ансамблевого подхода, включающего операцию мягкого голосования между моделями, для ряда технических мест удалось значительно улучшить качество предсказания на тестовой выборке. Наилучшие показатели наблюдаются для корпуса, улиты, электроаппаратуры и вибропреобразователя. Наиболее высокое качество предсказания получили технические места, неис-правная работа которых имеет быстрое развитие (электроаппаратура, вибропреобразователь, электродвигатель), а также с наиболее заметными и легко идентифицируемыми проявлениями неисправной работы (улита, корпус, вибропреобразователь). Следовательно, разметка данных для этих точек может производиться в более оперативном режиме, что важно для обучения моделей с учителем. Однако для остальных техузлов, несмотря на более низкие значения метрик, обученные модели предсказывают зарождение неисправности до момента идентификации ее сотрудниками, что позволит заранее подготовиться к развитию аномалии в работе оборудования и принять необходимые превентивные меры. Заключение Таким образом, с использованием разработанных моделей можно проводить исследова- ния работы эксгаустеров в режиме реального времени, а их результаты применять для планирования работ по оптимальному техническому обслуживанию. В текущем виде разработанное ПО может использоваться в пилотном проекте на одном из промышленных предприятий и покажет свою эффективность при прогнозировании неисправностей техузлов эксгаустера. В дальнейшем, в случае получения данных по другим типам оборудования, решение может успешно масштабироваться в комплексную систему предиктивной аналитики предприятия. Список литературы 1. James A.T., Gandhi O., Deshmukh S. Fault diagnosis of automobile systems using fault tree based on digraph modeling. Int. J. Syst. Assur. Eng. Manag., 2018, vol. 9, pp. 494–508. doi: 10.1007/s13198-017-0693-6. 2. Bhakta K., Sikder N., Nahid A.A., Islam M.M.M. Fault diagnosis of induction motor bearing using Cepstrum-based preprocessing and ensemble learning algorithm. Proc. Int. Conf. ECCE, 2019, pp. 1–6. doi: 10.1109/ECACE.2019. 8679223. 3. Трофимов В.В. Алгоритмизация и программирование. М.: Юрайт, 2017. 137 с. 4. Оклей П.И. Прогнозирование остаточного ресурса и вероятности наступления отказа оборудования – основа проектирования производственной программы ремонтных работ тепловой электростанции // Контроллинг. 2017. № 65. С. 54–63. 5. Nan X., Zhang B., Liu C., Gui Z., Yin X. Multi-modal learning-based equipment fault prediction in the internet of things. Sensors, 2022, vol. 22, no. 18, art. 6722. doi: 10.3390/s22186722. 6. Lv H., Chen J., Pan T., Zhang T., Feng Y., Liu Sh. Attention mechanism in intelligent fault diagnosis of machinery: A review of technique and application. Measurement, 2022, vol. 199, art. 111594. doi: 10.1016/j.measurement. 2022.111594. 7. Боровский А.С., Шумилина Н.А. Нечеткая ситуационная сеть для оценки проектного риска отказа оборудования // Тр. ИСА РАН. 2018. Т. 68. № 1. С. 87–93. 8. Xu Z., Mei X., Wang X., Yue M., Jin J., Yang Y., Li Ch. Fault diagnosis of wind turbine bearing using a multi-scale convolutional neural network with bidirectional long short term memory and weighted majority voting for multi-sensors. Renewable Energy, 2022, vol. 182, pp. 615–626. doi: 10.1016/J.RENENE.2021.10.024. 9. Антонов А.В. Методика статистического анализа данных об отказах оборудования АЭС в условиях неоднородного потока событий // Изв. вузов. Ядерная энергетика. 2016. № 3. С. 20–29. doi: 10.26583/npe.2016.3.03. 10. Cheng Y., Yuan H., Liu H., Lu C. Fault diagnosis for rolling bearing based on SIFT-KPCA and SVM. Eng. Computations, 2017, vol. 34, no. 1, pp. 53–65. doi: 10.1108/EC-01-2016-0005. 11. Mao W., Feng W., Liu Y., Zhang D., Liang X. A new deep auto-encoder method with fusing discriminant information for bearing fault diagnosis. MSSP, 2021, vol. 150, art. 107233. doi: 10.1016/j.ymssp.2020.107233. 12. Иванов В.К., Виноградова Н.В., Палюх Б.В., Сотников А.Н. Современные направления развития и области приложения теории Демпстера–Шафера // ИИиПР. 2018. № 4. С. 32–42. doi: 10.14357/20718594180403. 13. Javed K., Gouriveau R., Zerhouni N. State of the art and taxonomy of prognostics approaches, trends of prognostics applications and open issues towards maturity at different technology readiness levels. MSSP, 2017, vol. 94, no. 9, pp. 214–236. doi: 10.1016/j.ymssp.2017.01.050. 14. Hossain M., Abu-Siada A., Muyeen S. Methods for advanced wind turbine condition monitoring and early diagnosis: A literature review. Energies, 2018, vol. 11, no. 5, art. 1309. doi: 10.3390/en11051309. 15. Xiao C., Liu Z., Zhang T., Zhang X. Deep learning method for fault detection of wind turbine converter. Applied Sci., 2021, vol. 11, no. 3, art. 1280. doi: 10.3390/app11031280. 16. Пальчевский Е.В., Антонов В.В., Еникеев Р.Р. Прогнозирование на основе искусственной нейронной сети второго поколения для поддержки принятия решений в особо значимых ситуациях // Программные продукты и системы. 2022. Т. 35. № 3. С. 384–395. doi: 10.15827/0236-235X.139.384-395. 17. Kumar A., Kumar R. Time-frequency analysis and support vector machine in automatic detection of defect from vibration signal of centrifugal pump. Measurement, 2017, vol. 108, pp. 119–133. doi: 10.1016/j.measurement.2017.04.041. 18. Abbasi A.R., Mahmoudi M.R., Avazzadeh Z. Diagnosis and clustering of power transformer winding fault types by cross-correlation and clustering analysis of FRA results. IET Generation, Transmission & Distribution, 2018, vol. 12, no. 19, pp. 4301–4309. doi: 10.1049/iet-gtd.2018.5812. References 1. James, A.T., Gandhi, O., Deshmukh, S. (2018) ‘Fault diagnosis of automobile systems using fault tree based on digraph modeling’, Int. J. Syst. Assur., 9, pp. 494–508. doi: 10.1007/s13198-017-0693-6. 2. Bhakta, K., Sikder, N., Nahid, A.A., Islam, M.M.M. (2019) ‘Fault diagnosis of induction motor bearing using Cepstrum-based preprocessing and ensemble learning algorithm’, Proc. Int. Conf. ECCE, pp. 1–6. doi: 10.1109/ECACE.2019.8679223. 3. Trofimov, V.V. (2017) Algorithmization and Programming. Moscow, 137 p. (in Russ.). 4. Okley, P.I. (2017) ‘Predicting the residual service life and probability of failure of equipement – base of design of production program of repair works of thermal power plant’, Controlling, (65), pp. 54–56 (in Russ.). 5. Nan, X., Zhang, B., Liu, C., Gui, Z., Yin, X. (2022) ‘Multi-modal learning-based equipment fault prediction in the internet of things’, Sensors, 22(18), art. 6722. doi: 10.3390/s22186722. 6. Lv, H., Chen, J., Pan, T., Zhang, T., Feng, Y., Liu, Sh. (2022) ‘Attention mechanism in intelligent fault diagnosis of machinery: A review of technique and application’, Measurement, 199, art. 111594. doi: 10.1016/j.measurement.2022.111594. 7. Borovsky, A.S., Shumilina, N.A. (2018) ‘Unclear situational network for assessment of the design risk of equipment failure’, Proc. ISA RAS, 68, pp. 87–93 (in Russ.). 8. Xu, Z., Mei, X., Wang, X., Yue, M., Jin, J., Yang, Y., Li, Ch. (2022) ‘Fault diagnosis of wind turbine bearing using a multi-scale convolutional neural network with bidirectional long short term memory and weighted majority voting for multi-sensors’, Renewable Energy, 182, pp. 615–626. doi: 10.1016/J.RENENE.2021.10.024. 9. Antonov, A.V. (2016) ‘Statistical analysis of the nuclear power plant equipment failure data in nonhomogeneous failure flow’, Izv. Vuzov. Yadernaya Energetika, 3, pp. 20–29. doi: 10.26583/npe.2016.3.03 (in Russ.). 10. Cheng, Y., Yuan, H., Liu, H., Lu, C. (2017) ‘Fault diagnosis for rolling bearing based on SIFT-KPCA and SVM’, Eng. Computations, 34(1), pp. 53–65. doi: 10.1108/EC-01-2016-0005. 11. Mao, W., Feng, W., Liu, Y., Zhang, D., Liang, X. (2021) ‘A new deep auto-encoder method with fusing discriminant information for bearing fault diagnosis’, MSSP, 150, art. 107233. doi: 10.1016/j.ymssp.2020.107233. 12. Ivanov, V.K., Vinogradova, N.V., Palyukh, B.V., Sotnikov, A.N. (2018) ‘Modern directions of development and areas of application of the Dempster-Shafer theory’, Artificial Intelligence and Decision Making, (4), pp. 32–42 (in Russ.). doi: 10.14357/20718594180403. 13. Javed, K., Gouriveau, R., Zerhouni, N. (2017) ‘State of the art and taxonomy of prognostics approaches, trends of prognostics applications and open issues towards maturity at different technology readiness levels’, MSSP, 94(9), pp. 214–236. doi: 10.1016/j.ymssp.2017.01.050. 14. Hossain, M., Abu-Siada, A., Muyeen, S. (2018) ‘Methods for advanced wind turbine condition monitoring and early diagnosis: A literature review’, Energies, 11(5), art. 1309. doi: 10.3390/en11051309. 15. Xiao, C., Liu, Z., Zhang, T., Zhang, X. (2021) ‘Deep learning method for fault detection of wind turbine converter’, Applied Sci., 11(3), art. 1280. doi: 10.3390/app11031280. 16. Palchevsky, E.V., Antonov, V.V., Enikeev, R.R. (2022) ‘Forecasting based on a second-generation artificial neural network to support decision-making in critical situations’, Software & Systems, 35(3), pp. 384–395 (in Russ.). doi: 10.15827/0236-235X.139.384-395. 17. Kumar, A., Kumar, R. (2017) ‘Time-frequency analysis and support vector machine in automatic detection of defect from vibration signal of centrifugal pump’, Measurement, 108, pp. 119–133. doi: 10.1016/j.measurement.2017.04.041. 18. Abbasi, A.R., Mahmoudi, M.R., Avazzadeh, Z. (2018) ‘Diagnosis and clustering of power transformer winding fault types by cross-correlation and clustering analysis of FRA results’, IET Generation, Transmission & Distribution, 12(19), pp. 4301–4309. doi: 10.1049/iet-gtd.2018.5812. |
| Permanent link: http://swsys.ru/index.php?id=5084&lang=en&page=article |
Print version |
| The article was published in issue no. № 2, 2024 [ pp. 254-261 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Нейросетевой метод обнаружения вредоносных программ на платформе Android
- Прогнозирование угроз в сложных распределенных системах на основе интеллектуального анализа больших данных автоматизированных средств мониторинга
- Комплекс программ для индуктивного формирования баз медицинских знаний
- Разработка модификации метода опорных векторов для решения задачи классификации с ограничениями на предметную область
- Метод адаптивной классификации изображений с использованием обучения с подкреплением
Back to the list of articles